Year I Progress Report for
NSF Grant IRI-9711951
Information Technology and Organizations
--
"Conceptual Frameworks and Computational Support
for Organizational Memories and Organizational Learning (OMOL)"
Center for LifeLong Learning and Design (L3D)
Department of Computer Science
And Institute of Cognitive Science
University of Colorado
Boulder, CO 80309-0430
Principal Investigators:
Gerhard Fischer
Jonathan Ostwald
Gerry Stahl
Other Supported Personnel:
Gabe Johnson
Kate Ingmundson
Barb Stuart
Jessica Witter
Other Participants:
Taro Adachi
Yoshikazu Hayashi
Thomas Herrmann
Tim Koschmann
Shigera Kurihara
Frieder Nake
Rogerio dePaula
Brent Reeves
Masanori Sugimoto
Yunwen Ye
Year I of the Organizational Memories and Organizational Learning (OMOL) Research Project focused on the start-up of a variety of activities to explore conceptual frameworks of the field using several computational support prototypes. The following Report documents this work and reflects on its inherent unity. The report will be made into a web site and will be maintained to track continuing progress.
The major achievement in the Project's first year has been the creation of an exciting intellectual environment for exploring organizational memory and organizational learning. In addition to the three PIs on the project, fourteen students, visiting researchers and consultants participated in the project team, attending weekly meetings and helping to develop the theories and software. Through collaborations with other groups, the use of supplementary funding sources and the involvement of volunteers, the project leveraged a considerable workforce. This community will provide an important testbed for investigating computational supports for collaboration and for self-reflection.
The proposed goals of Year I were met and an effective foundation for the work of Year II and III was laid. The Year I activities resulted in a more concrete vision of how organizational memories can be designed to support organizational learning. The theoretical framework was operationalized in specific software prototypes, such as dynamic web sites to capture organizational communication and history. In Years II and III, these ideas will be explored through continued theoretical research, further software prototyping and assessment in group use situations.
The Year I Progress Report is divided into two parts: "Conceptual Frameworks" and "Computational Support". These are followed by sections on "Human Resources Development", "Publications", "Invited Talks" and "Financial Report".
In the proposal for the NSF OMOL Research Project, we discussed support for learning within communities of practice. We used the example of local area network (LAN) management teams. During Year I, we conducted ethnographic studies of this community and developed a prototype software system, WebNet, to serve as an organizational memory for them. We submitted a paper co-authored by the project PIs to CSCW ’98, entitled "Collaborative Information Environments for LifeLong Learning in Communities". In this paper and a number of other forums, we developed a conceptual framework for collaborative information environments (CIEs). CIEs differ from domain-oriented design environments (DODEs) of our previous work primarily in that their knowledge base is designed more to capture communication and history of the user community than to contain domain knowledge of a profession. This shift has a number of implications for organizational memories and organizational learning.
At a theoretical level, the unit of analysis is shifted from the individual designer to a community of practice: the history, memory, concerns, concepts, roles, relationships and activities of the social unit. The traditional approach of knowledge-based systems that elicited knowledge from textbooks, manuals and experts is inadequate; the discourse of the community must be captured, systematized and made available. Our theoretical reflections – reviewed in Part I of this Report – identify a number of concerns and principles related to this conceptualization of organizational memory.
The WebNet prototype sketches the idea of a collaborative information environment (CIE). It includes a design component similar to our DODEs, in which a LAN is designed and the system critiques it based on domain-specific rules. Critics deliver links to relevant sites on the web for information related to the problem that was critiqued. WebNet also includes a database of community-specific history about how the local LANs are configured and about problems that have been encountered and solved. In addition, WebNet provides a medium of communication for the LAN community of practice: discussion forums and an email repository, for instance. While WebNet illustrates the CIE concept, the details of how to structure its individual components remain to be worked out before such a system can be disseminated. Therefore, we began work on a variety of prototypes to explore specific mechanisms of dynamic organizational memories.
As detailed in Part II of this Report, DynaSites is a set of dynamic web sites that allow a community to build their organizational memory while they are communicating. GIMMe-More archives a community’s email to serve as a memory. Mediator explores the utility of usage data that is implicit in an organizational memory as information for structuring the memory automatically. ScrapWeb and WebGuide help communities organize and learn from web research. State the Essence and SimRocket support classroom learning while Mr. Rogers and Community Trails support communities of interest.
In Years II and III, these and other specific mechanisms of organizational memory will be explored in software prototypes and used by testbed communities. Among the mechanisms to be explored are discussion forums, evolvable glossaries, virtual libraries, perspectives, negotiation, usage data and collaborative component libraries. Among the testbed communities are classrooms at the K-12 and university levels, research groups, neighborhood interest groups and industrial teams.
Executive Summary *
Conceptual Frameworks
*Computational Support
*
Table of Contents *
Part I: Conceptual Frameworks *
Overview
*Analysis of WebNet Prototype
*DynaSites
*GIMMe-More
*Mediator and Theories of Usage Data
*ScrapWeb Personal Information Space Management
*WebGuide Support for Perspectives and Negotiation
*A Discussion is not a Tree
*Collaboration on the Experience Factory
*Community Trails
*Courses as Seeds
*Course on Computer-Supported Collaborative Learning
*Course on Designing the Information Society of the Next Millennium
*Philosophy of Undergraduate Research Apprenticeship Program
*Studies of Evolving Repositories
*Book on Domain-Oriented Design Environments
*The Sources Project
*
Part II: Computational Support *
Overview
*WebNet
*DynaSites
*GIMMe-More
*Mediator
*ScrapWeb
*WebGuide
*State the Essence
*
Human Resources Development *
Publications *
Invited Talks *
Financial Report *
List of Figures and Tables
Figure 1: Cycles of Design, Computer Support and Organizational Learning *
Figure 2: Comparison of DODE to CIE . *
Figure 3: Making the World Wide Web a Medium for Collaborative, Evolutionary Design *
Figure 4: Usage Data Supporting Organizational Memory *
Figure 5: Multilayering Representation of a Collaborative Discussion *
Figure 6: Embedded Communication *
Figure 7: A Conceptual Framework for Reuse *
Figure 8: WebNet Home Page Showing WebNet Interface *
Figure 9: DynaSites Structure *
Figure 10: DynaGloss Features *
Figure 11: DynaSources Interface *
Figure 12: Mr. Rogers' Sustainable Neighborhood. *
Figure 13: GIMMeMore Architecture *
Figure 14: Module Architecture of the Mediator Prototype System *
Figure 15: Architecture of ScrapWeb *
Figure 16: Export A URL into ScrapWeb *
Figure 17: Search URLs Interface *
Figure 18: Kay's Personal Perspective *
Figure 19: Negotiation Perspective *
Figure 20: Inheritance of Perspectives *
Table 1: Design Requirements Summary *
Table 2: Comparison of Object Economies Supporting Communities of Practice *
Table 3: How Our Prototypes Were Used to Achieve OMOL Project Goals *
Our work on organizational memory and organizational learning (OMOL) is an extension of our work on domain-oriented design environments (DODEs). The unit of analysis has shifted from individuals to communities of practice (CoPs). For our purposes, CoPs are cooperating teams with common objectives and tasks that form within or across organizations. They differ from communities of interest (CoIs) in that CoIs share only common goals.
Based on our experiences at the Center for LifeLong Learning and Design (L3D) at the University of Colorado at Boulder (University), we have concluded that technological changes must be accompanied with changes in practice in order to be effective. Consequently, the projects that we used to develop a conceptual framework encompass both issues of computational support and social practices. In the process of developing software prototypes, we extended our list of necessary OMOL computational support features. We also examined alternative computational mechanisms such as acyclical digraphs, dynamic and end-user modifiable information spaces, and perspectives and negotiation to address some of our findings from the implementation of the prototypes. To understand different social practices and the implications of changes to social practice, we observed and experimented with social practices and changes in these practices within the University and in industrial settings. In addition, we examined evolving CoI repositories, reviewed existing literature on OMOL issues, and reflected on L3D's development of DODEs. Specifically, we developed the following software prototypes, and pursued the following social practice projects during Year I of the OMOL Project.
WebNet: A prototype developed to explore support for CoPs. We proposed WebNet as our major prototyping effort for Year I. Our assessment of our experience with WebNet set the direction of the OMOL project for the remainder of Year I and will influence our work in Years II and III.
DynaSites: A prototype developed for storing evolving organizational memories (OMs) and presenting the contents of the OMs dynamically.
GIMMe-More: A prototype for archiving email developed as part of a doctoral dissertation in which we focused on group memory theories.
Mediator: A prototype for exploring usage data as a form of knowledge for organizational memories, developed as part of master’s thesis.
ScrapWeb: A prototype for exploring methods of reducing the cognitive load on users of OMs by providing them with personal information space management tools, developed by a Ph.D. student at L3D as a class project.
WebGuide: A conceptual design of mechanisms for the creation and maintenance of OM perspectives and negotiation supports.
A Discussion is Not a Tree: A conceptual computational framework for supporting computationally-mediated collaborative discussions developed as a masters thesis.
Experience Factory: A collaboration between us and researchers at Daimler-Benz in Germany. With the Daimler-Benz researchers, we are developing an approach to OMOL in industrial settings.
Community Trails: An observation of the use of a computational OM (a discussion forum) by a CoI (a neighborhood organization).
Courses as Seeds: A conceptual framework for organizational learning using organizational memory at the university level.
CSCL course: A graduate seminar on computer supported collaborative learning. The course used our DynaClass prototype as a tool for organizational memory and organizational learning. We reflected at length on the relation between this tool and the classroom practices that evolved to take advantage of it.
Designing the Information Society of the Next Millennium course: A cross-disciplinary, graduate and undergraduate course in which we explored issues of life long learning, the impacts of technology on society, and the use of electronic discussion forums as organizational memories.
Undergraduate Research Apprenticeship Program: An undergraduate apprenticeship program. We began offering apprenticeships at L3D to provide opportunities for creative and engaged undergraduates to develop a passion and deep personal interesting in learning, working and collaborating as part of our efforts in understanding the development of communities of practice.
Examination of Evolving Repositories: An analysis of two organizational memories developed outside of our project – Gamelan and Educational Object Economy.
DODEs book: A book-length reflection on our work with domain-oriented design environments (DODEs). In the book, we discuss our explorations of DODEs of more than a decade, culminating in the WebNet prototype.
Literature Sources: A review of literature on OMOL issues. We began to collect and organize important and useful sources of information about OMOL.
From these projects, we have learned that computer-based organizational memories (OMs) must be matched with new social structures that produce and reproduce patterns of organizational learning. Community memories are to communities of practice what human memories are to individuals. They make use of explicit, external, symbolic representations that allow for shared understanding within a community. They make organizational learning possible within the group. Community memory needs to be treated as constantly evolving and largely specific to a particular community of practice. As such, computer-based OMs must
have capture mechanisms that reduce the effort required to contribute and participate in a computational OM to below the benefit gained from using the computational OM,
have mechanisms to support the collaborative evolution of the space by community members,
support members in locating, retrieving, comprehending and modifying items in the OM,
embed context into the information,
deliver the right information, at the right time in the right way, and
support and allow for the representation of acyclical (i.e., non-hierarchical collaborative discussions and design activities).
Our reflections on the conceptual issues of each of the above projects are described below.
Our initial system building efforts of the OMOL project centered on WebNet, as proposed in our funding proposal. WebNet is a web-based organizational memory developed to support organizational learning within a community of local-area network (LAN) managers. The software itself will be discussed below in the section on computational support. In terms of our conceptual framework, WebNet helped us to understand a number of theoretical issues better. In particular, we conceptualized a new way of thinking about multi-faceted support systems and began to talk about Collaborative Information Environments (CIEs) rather than DODEs. This transition had to do with what we learned about communities of practice, like LAN management teams.
All work within a division of labor is social. The job that one person performs is also performed similarly by others and relies upon vast social networks. Work is defined by social practices that are propagated through socialization, apprenticeship, training, schooling, and culture, as well as by explicit standards. Often, work is performed by cooperating teams that form communities of practice within or across organizations.
Our interviews showed that computer network managers at our university work in concert. They need to share information about what they have done and how it is done with other team members and with other LAN managers elsewhere. For such a community, information about their own situation may be even more important than generic domain knowledge. Support for LAN managers must provide community memory about how individual local devices have been configured as well as offer domain knowledge about standards, protocols and compatibility.
Communities of practice can be co-located within an organization (e.g., at our university) or across a discipline (e.g., all directors of university networks). Before the World Wide Web existed, most computer support for communities of practice targeted individuals with desktop applications. The knowledge in the systems was mostly static domain knowledge. With intranets and interactive web sites, it is now possible to support distributed communities and also to maintain evolving information about local circumstances and group history.
Human and social evolution can be viewed as the successive development of increasingly effective forms of memory for learning, storing and sharing knowledge. Biological evolution gave us episodic and mimetic memory; then cultural evolution provided mythical, oral and written¾external and shared¾memory; finally modern technological evolution generates digital (computer-based) and global (Internet-based) memories.
The development of hardware capabilities must be followed by the adoption of appropriate skills and practices before the potential of the new information technology can be realized. External memories, incorporating symbolic representations, facilitate the growth of complex societies and sophisticated scientific understandings. Their effectiveness relies upon the spread of literacy and industrialization. Similarly, while the proliferation of networked computers ushers in the possibility of capturing new knowledge as it is produced within work groups and delivering relevant information on demand, the achievement of this potential requires the careful design of information systems, software interfaces and new work practices. Computer-based community memories must be matched with new social structures that produce and reproduce patterns of organizational learning.
Community memories are to communities of practice what human memories are to individuals. They make use of explicit, external, symbolic representations that allow for shared understanding within a community. They make organizational learning possible within the group.
The ability of individual designers to proceed based on their tacit existing expertise periodically breaks down, and they have to rebuild their understanding of the situation through explicit reflection. This reflective stage can be helped if they have good community support or effective computer support to bring relevant new information to bear on their problem. When they have comprehended the problem and incorporated the new understanding in their personal memories, we say they have learned. The process of design typically follows this cycle of breakdown and reinterpretation (see Figure 1, cycle on left).
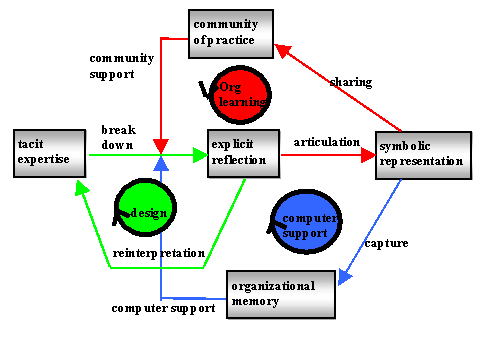
Figure 1. The cylce of organizational learning
A similar process takes place at the group level, involving interaction between the community and its members. When design tasks take place in a collaborative context, the individual team members’ reflections result in articulation of solutions in language or in other symbolic representations. The articulated new knowledge can be shared within the community of practice. Such knowledge, learned by the community, can be used in future situations to help a member overcome a breakdown in understanding. This cycle of collaboration is called organizational learning (see Figure 1, upper cycle). The interaction of multiple personal perspectives and the collaborative articulation of shared perspectives makes innovation possible by allowing new knowledge to be built on past knowledge.
Organizational learning can be supported by computer-based systems if the articulated knowledge is captured in a digital symbolic representation. The information must be stored and organized in a format that facilitates its subsequent identification and retrieval. In order to provide computer support, the software must be able to recognize breakdown situations when particular items of stored information might be useful to human reflection (see Figure 1, lower cycle). DODEs provide computer support for design by individuals. They need to be extended to Collaborative Information Environments (CIEs) to support organizational learning in communities of practice.
Extending the DODE Approach to CIEs
The key to active computer support that goes significantly beyond printed external memories is to have the system deliver the right information at the right time in the right way. Somehow, the software must be able to analyze the state of the work being undertaken, identify likely breakdowns, locate relevant information and deliver that information in a timely and useful manner.
DODEs like NetSuite and our older prototypes used critics based on domain knowledge to deliver information relevant to the current state of a design artifact being constructed in the design environment work space (see Figure 2, left).
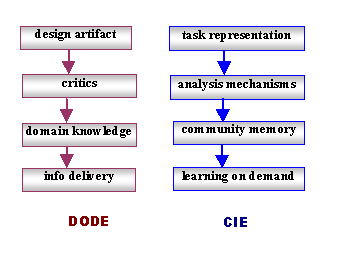 Figure 2. From DODE to CIE.
Figure 2. From DODE to CIE.
One can generalize from the critiquing approach of these DODEs to arrive at an overall architecture for CIEs. The core difference between a DODE and a CIE is that a DODE focuses on delivering domain knowledge, conceived of as relatively static and universal, while a CIE is built around forms of community memory, treated as constantly evolving and largely specific to a particular community of practice. Where DODEs relied heavily on a set of critic rules predefined as part of the domain knowledge, CIEs generalize the function of the critiquing mechanisms.
In a CIE, it is still necessary to maintain some representation of the task as a basis for the software to take action. This is most naturally accomplished if work is done within the software environment. If communication about designs takes place within the system where the design is constructed, then annotations and email messages can be linked directly to the design elements they discuss. This reduces deictic comments (comments referring to "that" object "over there" in a design). It allows related items to be linked together by automatic analysis mechanisms. In a rich community memory, there may be many relationships of interest between new work artifacts and items in the information spaces. For instance, when a LAN manager debugs a network then links between network diagrams, topology designs, LAN diary entries, device tables or an interactive glossary of local terminology can be browsed to discover relevant information on demand.
The general problem for a CIE is to define analysis mechanisms that can bridge from the task representation to relevant community memory information items to support learning on demand (see Figure 2, right).
To take a very different example, suppose you are writing a paper within a software environment that includes a digital library of papers written by you and your colleagues. Then an analysis mechanism to support your learning might compare sentences or paragraphs in your draft (which functions as a task representation) to text from other papers and from email discussions (the community memory) to find excerpts of potential interest to deliver for your learning. We use latent semantic analysis to mine our email repository and are exploring similar uses of this mechanism to link task representations to textual information to support organizational learning.
The impetus for our extending DODEs into CIEs came partially from the advent of the World Wide Web. This technology facilitates the sharing and collaborative evolution of information and computer support within a community of practice—even within dispersed or virtual communities. In 1996/97 we prototyped WebNet, a CIE for LAN management communities, as a web-based intranet. It includes a variety of communication media as well as community memory repositories and collaborative productivity tools. Our work on WebNet started with ProNet, a Mac-based DODE for LAN design that was gradually adapted to the web.
The web has the potential to support the interactivity needed for CIEs to maintain community memories. Dynamic web pages can be interactive in the sense that they accept user inputs through selection buttons and text entry forms. Unlike most forms on the web that only provide information (like product orders, customer preferences or user demographics) to a site webmaster, intranet feedback may be made immediately available to the user community that generated it.
DynaSites is an evolvable and dynamic web-based OMs developed to support organizational learning. It has been used by many communities at the University - our project team, classes offered by L3D, software prototypes supporting CoIs (e.g., Mr. Roger's) - and at New Vista High School. The software itself will be discussed below in the section on computational support. You can use DynaSites by visiting http://seed.cs.colorado.edu/dynasites.Documentation.fcgi. DynaSites helped us to understand issues surrounding evolvable and dynamic OMs in the context of traditional uses of the Web.
Historically, the Web has been used as a Broadcast Medium (Figure 3, Model M1). Information is placed on static Web pages and there is little opportunity for users to interact with the information. Many Web sites are evolving into a form that combines Broadcast with Feedback (M2). In the process of exploring such an information space, users can provide feedback and ask questions via email or by filling out forms. An essential requirement for OMs supporting OL is to have a third model for the Web: evolutionary and collaborative design (M3). In this model, users can use the Web to collaborate on projects, perform in-depth research on certain aspects of a project, and learn from their peers.
The M3 model poses a number of technical challenges that we explored with the implementation of DynaSites, including the ability to:
add to an information space without going through an intermediary,
modify the structure of the information space,
modify at least some of the existing information, and
make argumentation contained in the information space serve design by integrating the discussion about the design into the information space itself.
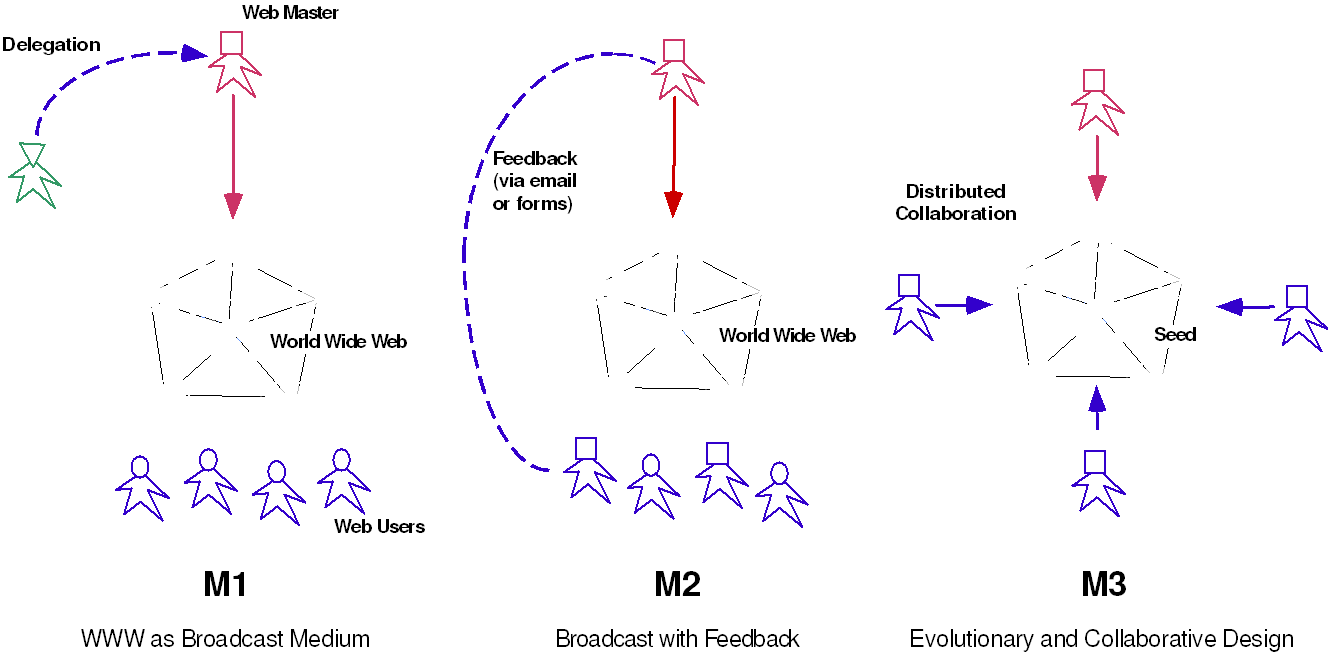
Figure 3: Making the World Wide Web a Medium for Collaborative, Evolutionary Design
In the process of developing GIMMeMore, we focused on group memory theories, focusing on the notion of CoPs and the process of OL. In this report, we describe CoPs and the process of OL in our Analysis of WebNet prototype. The GIMMeMore software prototype is described in the section on computation support.
Mediator and Theories of Usage Data
We explored the use of usage data as a free (to the user) method of enhancing OMs. We describe the Mediator prototype in the computational support section of this report, and focus here on the theoretical underpinnings of Mediator.
There are increasing opportunities for workers in organizations to form CoPs. Workers form communities because they have more demands on knowledge sharing and collaborative problem solving as their tasks become more knowledge intensive. In a CoP for which the target domain is changing fast, no individual knows every thing, and members need to teach each other and mutually learn. Because learning is necessary within the context of working, learning and teaching between members are often peer-to-peer. OM is one of the major components supporting CoPs because it is a medium of such complex communications held within CoPs as mutual learning, peer-to-peer-learning, learning on demand, single-loop and double-loop learning, and direct and indirect communications.
Usage data can be used to meet the OM challenges. We introduce a new category of tools called usage data aware (UDA) tools that utilize usage data to improve the functions of OMs. Usage data 1) are basically available at little additional cost in terms of the information providers’ effort, 2) reflect general activities taken to solve problems, 3) could be used to define clusters of information that are useful for information browsing, and 4) are useful for tracking the evolution of OM. For usage data to be useful for an OM, the following functionality must exist 1) capture of usage data, 2) collection of individuals’ usage data, 3) utilization of collective usage data, 4) modification and refinement of collective usage data, and 5) modification and refinement of capturing and utilization methods.
We have conceptualized a system to improve OMs for CoPs - Mediator. In Figure 4, we show how Mediator improves OMs for CoPs. In the left smaller box, Mediator captures and collects usage data and users utilize collective usage data, also users can modify and refine the collective usage data. In the right smaller box, OM environment designers modify and refine how the system captures usage data and UDA tools utilize the captured usage data. The modified environment is reregistered as a new environment.
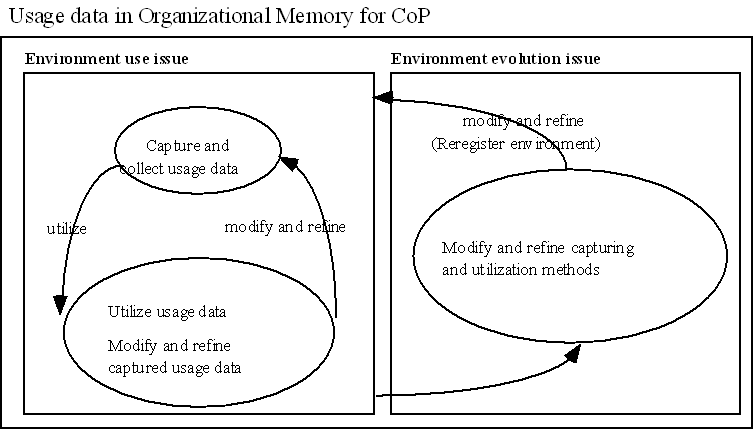
Figure 4: Usage Data Supporting Organizational Memory
We expect that with various types of UDA tools members of communities can improve OM in terms of environment use and environment evolution. Consequently, members of communities can receive more support in knowledge sharing and collaborative problem solving from other members.
ScrapWeb Personal Information Space Management
ScrapWeb is a software prototype developed to reduce the cognitive load required by users of OMs, specifically users of the WWW to organize personal information space. The prototype is described in detail in the computational support section of this report.
A survey investigating the use of World Wide Web, it was revealed that the top four problems that web users identified with using the World Wide Web are:
It takes too long to view/download pages (69.1%).
They are unable able to find a page that they know exists (34.5%).
Users are unable to organize the pages and information they gather (25.8%).
Users are unable to find a page that they once visited (23.7%)
The first problem is mainly caused by heavy network traffic and may be improved by increasing the network infrastructure. The second problem is the broken link problem which is related to the naming mechanism of URL. The third and fourth problems are related. Because people are not sure how to organize the pages and information that they have gathered, they hesitate in gathering more information and thus they are not able to find a previously visited page when their memory fades. We call the combination of these two problems the personal information space management problem.
We identified some core challenges to personal information space management:
Indexing and contextualization of information - A flexible, multidimensional indexing mechanism is necessary to address the unpredictability of indexing items used at retrieval, and to overcome the shortcoming that human beings remember things vaguely. It is difficult for human beings to remember something outside of a context. For example, underscores and annotations made to reading materials are important ways of preserving these contexts. When users come back to recover memory, the contexts become very good hints.
Filtering - An arising research area of helping users find interesting information over the Internet is the development of recommender systems, such as PHOAKS (People Helping One Another Know Stuff) and Referral Web. Recommender systems, also known as collaborative filtering are motivated by the observation that "in everyday life, we rely on recommendations from other people either by word of mouth, recommendation letters, movie and book reviews printed in newspapers, or in general surveys. Specifically, with the ScrapWeb prototype we explored the notion of self-recommendation.
Storage of serendipitous web pages - As Berstein has pointed out, the "value of hypertext lies in its ability of creating serendipitous connections between unexpected ideas", the support to manage those web pages that are serendipitously exposed to users is not enough. Serendipitous web pages are likely numerous; users’ interest in them varies greatly. Cataloging of them is more difficult; as the chance and the context of revisiting are more difficult to predict. This is a problem of delivering the right information, at the right time, in the right way.
Uniform interface -From the point view of information carrier, emails and web pages do not have much difference; it is not necessary to separate them into two different world, and when users want to find some pieces of information that they uncertainly remember, they may not remember its origin. This is a related problem to integrating an OMOL tool with domain tools.
WebGuide Support for Perspectives and Negotiation
We are in the process of prototyping a system that integrates perspective and negotiation mechanisms. The system is called WebGuide. Its user interface has been mocked up in detail to work out the many issues involved. The mock up is presented on the Web at http://GerryStahl.net/WebGuide/webguide.htm. The WebGuide software will be discussed in the computational support section of this report.
Collaborative work typically involves both individual and group activities. Computer support for perspectives allows people to view and work on a central information repository in personal contexts. By intertwining perspective and negotiation mechanisms, individual results can be systematically merged into a group product while work continues. Personal perspectives on shared information are thereby intertwined and merged into a shared group understanding.
The web provides an obvious medium for collaborative work. However, it provides no support the interplay of individual and group understanding that drives collaboration. First, we need ways to find and work with information that matches our needs, interests, and capabilities. Then, we need means for bringing our individual knowledge together to build a shared understanding and collaborative products. The web must be enhanced with perspective and negotiation mechanisms to accomplish this.
The term perspective means that a particular, restricted segment of an information source is being considered, stored, categorized, and annotated. In the realm of collaborative work, it is important to intertwine personal perspectives with each other. An individual can do this by taking into account the perspectives of others or by adopting part of another person’s perspective within one’s own. It is also possible to merge several perspectives into one common one. In work on WebGuide, we explore the possibility of providing computer support for intertwining perspectives in collaborative work.
Our approach combines previous research we conducted on computer support for perspectives and for negotiation. Computer support for perspectives allows people in a group to interact with a shared information source; everyone views and maintains their own perspective on the information without interfering with content displayed in the perspectives of other group members. The problem is that perspectives of group members tend to diverge rather than converge as work proceeds. Computer support for negotiation can help by allowing members of a group to communicate about what information to include as mutually acceptable. The problem with negotiation is that it delays work on information while potentially lengthy negotiations are underway. Here, perspectives provide a solution, allowing work to continue within personal perspectives while the contents of shared perspectives are being negotiated.
We believe that perspectives and negotiation are each important CSCW concepts in their own right, but that when combined they can offset each other’s major weaknesses and provide powerful support for shared information sources. We propose an approach to intertwining the mechanisms of perspectives and negotiation to help collaborative groups intertwine the personal perspectives of their members into an effective shared network of perspectives on task-relevant information.
While reviewing the structure and contents of discussion forums as they relate to the requirements of a computer supported collaborative learning environment, we concluded that computationally-mediated threaded discussion forums are limiting. They are restricted to a hierarchical - tree - structure. On the other hand, participants in collaborative discussions are not restricted to a single thread of thought; they construct their arguments through a complex intertwining of different ideas, references, perspectives and examples.
To computationally support collaborative discussion forums, a more complex structure than a hierarchy is needed to capture and foster the complex inter-relations. Acyclical-digraph (DAG, directed-acyclical-graph) structures offer a conceptual framework for computationally-mediated discussions that support such complex intertwinings. DAG is a mathematical model that supports the complex interrelation of nodes, and provides the necessary functionality to support the complex interrelations of discussion threads. It can provide participants of a computer conference the opportunity to engage in richer conversations by facilitating the linking of ideas, mutual interest overlapping and convergent knowledge building - going beyond turn-taking, disagreement-and-repairing, and argument-and-counter-example - extending then a threaded discussion forum into a "collaborative discussion forum."
Mathematically, Chartrand & Lesniak describe directed graph as, "a finite nonempty set of objects called vertices together with a [...] set of ordered pairs of distinct vertices of D called arcs or directed edges." The acyclical nature of acyclical-digraphs ensures that there is no loop back in any element of the digraph. The acyclical nature of DAGs is important for supporting discussions, because of the temporality of discussions - it is not possible for an element to refer to another element that has not been introduced yet.
The dimensions of a collaborative practice that need to be incorporated into a DAG structured discussion are actors, thematic material, perspectives, and references. Each vertex, or node, represents an actor in a discussion, therefore, it will be labeled by his/her name, or initials. The starting node of a discussion is called a root, and it has no prior reference in a specific discussion. The root node has only one or more outgoing edges. The branch nodes can have incoming and outgoing edges. The ending nodes, called leaves, have only incoming edges. An interesting way of representing a discussion would be via a Cartesian graph, in which the horizontal axis represents the time, and the vertical axis qualitatively represents the "distance" between nodes. See Figure 5. This "distance" qualitatively represents the relationship between nodes in terms of content, for instance, it can represent the extent of agreement or disagreement. The arrows that arrive at a node represent all the previous references that the content of the node are related to, i.e., different perspectives. The colors represent a topic or theme of a discussion. This is a multilayering representation.
While DynaSites (described in this report) supports the acyclical nature of collaborative discussions through links, the user is unable to get a bird's eye view of this and consequently the interconnectedness of threads is not apparent. Therefore, another important element of this research is that in addition to supporting a DAG structure, the representation of this structure is also critical.

Figure 5: Multilayering Representation of a Collaborative Discussion
For more details visit http://ucsu.Colorado.EDU/~depaula/papers/notatree.htm.
Collaboration on the Experience Factory
In a collaborative effort with the research center of Daimler-Benz in Ulm, Germany, we have reflected on the nature of an organizational memory that supports organizational learning. During this process, we developed some principles to guide the design of computational OMOL support systems. To summarize these: most people need to perceive a benefit to participating in an OMOL system. An explicit representation of the tradeoff between expected payoff and effort is:
utility = value / effort
i.e., only if they perceive that their benefit outweighs the required effort will they decide to participate (e.g., provide design rationale, document the answer to frequent question etc.). Broadly, we envisioned the features of such as system to meet the requirements shown in Table 1.
Table 1: Design Requirements Summary
| In relation to… | The System Must… | so that... | To avoid... |
| User | Benefit | user need not do extra work just for the group | Under use of the system |
| Protect | to encourage honest input and feedback | Saying what the user expects the system expects | |
| Remember actions | rely on easy access to history use of system for designing, exploring |
Using system only as repository | |
| Respect tacit knowledge | user need not make explicit what is currently socially kept tacit | Working "around" the system instead of through it | |
| Process | Support | system will meld into the background | Technological discomfort/distrust |
| Respect | old wisdom/pragmatic experience not lost | Major/catastrophic failures around exceptions | |
| Transcend | people may continue to grow and challenge old knowledge | Tunnel-vision | |
| Group | Facilitate dt/dp | maximum leverage of individual’s expertise across time and distance | Duplication of effort |
| Artifacts | Remember changes | retain living explanation | "Reinventing the wheel". |
| Integrate with communication | preserve context of communication maximize learning from past |
Delivery of decontextualized, and consequently meaningless, information |
We abstracted from our experiences with work groups some principles for OMOL computational support systems. In so doing, we considered the importance of design rationale, the finiteness of individual time and effort, the utility of a reflexive system (in other words a system that supports the group as well as the individual), the uniqueness and highly evolved nature of social customs within CoPs, the need to respect and not interrupt the flow of work by forcing users of an OM to explicate knowledge, the need to preserve context and tacit knowledge when storing communicational exchanges, and recognizing that motivated users can increase the chances of system success and that a system can reduce or increase a users motivation. The principles are as follows:
Principle 1: The system must be of immediate benefit to the current user.
Principle 2: The system must protect the current user.
Principle 3: The system must not interfere with the current work.
Principle 4: The system must support the process as well as the product.
Principle 5: The system must respect social custom.
Principle 6: The system must not appear arbitrary to the user.
Principle 7: The system must build on people's use of tacit knowledge.
Principle 8: The system must remember what people have already done.
Principle 9: The system must integrate artifact and communication (see Figure 6).
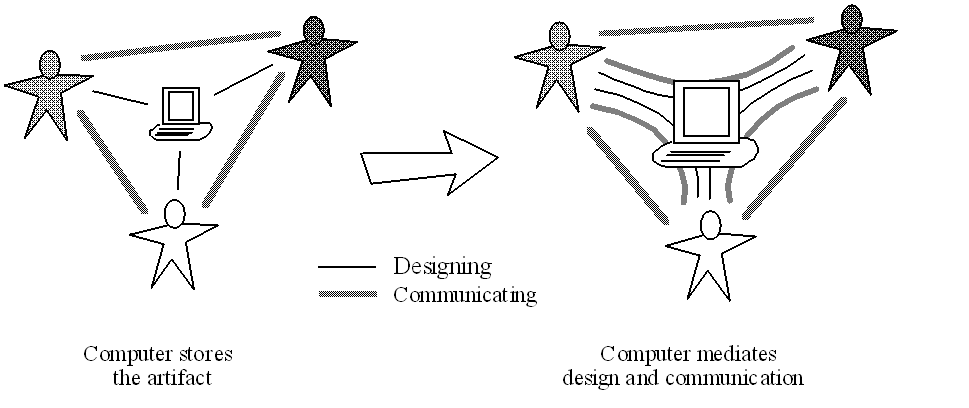
Figure 6: Embedded Communication
Principle 10: The system must exist in an environment of motivated users.
Principle 11: The system must provide a growth curve matched to the varying skill levels of users.
Principle 12: The system must provide access to real practitioners and experts.
The Community Trails web site was developed to explore the use of an organizational memory for a neighborhood organization engaged in a typical battle with local government. Because of its controversial nature, this project was done outside of work time and without use of University resources or NSF support. However, it was conducted by a member of the OMOL project as part of the project's set of interests. The web site served a number of purposes:
It provided a structured repository of documents related to the conflict: neighbor's testimony, newspaper articles, letters to the editor, official and alternative trail maps, etc.
It provided a monitored forum for debate about the issue: emails sent to participants were posted along with responses to them.
It provided a public medium for the organization's views: the site was advertised in the local and neighborhood papers, and provided an alternative to them.
It demonstrated a level of seriousness of the neighbors. In fact, a large number of web site hits were from the opposed government agency.
It allowed the organization to respond to unfriendly views and put them in context with annotations and links to other documents.
After a couple of months the effort of maintaining the site became too much for volunteers to continue. However, people continued to refer to it. Subsequently, the general homeowners association decided to build a web site to display other information (minutes, correspondence, covenants).
It was clear from this experience that the public media are inadequate for representing events like this. Reporters always look for controversy, even if they have to stir it up with slanted headlines, pictures and quotations. They put a spin on events that distracts from the central issues and brings up extraneous issues. Letters to the Editor respond to newspaper reporting by attacking one side or the other emotionally and with little depth of understanding. Of course, it is not always possible to get coverage at all and one never knows how much the papers are politically aligned with particular local governmental agencies. For instance, when a decision was finally made at a late night meeting, the reporter covering it left early and misreported the final decision; when informed about a long list of misinformation, she refused to publish a correction. It was only via media in the hands of the community that a clear story could be circulated. The community trails web site is available at http://www.tridog.com/nrlvtc
We prepared a paper in which we discussed a new framework for courses - courses-as-seeds. The courses-as-seeds idea provides a direction for exploration in many domains of lifelong learning in which communities of practice engage collaboratively in the incremental construction of knowledge in the context of a course. The courses-as-seeds idea provides a model for learning in a knowledge society that is built upon distributed cognition, articulate learners, peer-to-peer learning, and incremental enhancement of information spaces by a community of practice. This kind of idea develops when people with different but related aims come together.
The "courses as finished products" (the model currently practiced by most institutions) is built upon the following characteristics:
a course is offered (perhaps in a distance learning environment) and learners answer problems given to them in the course by the instructor;
the course will be given over a period of years more or less in the same form;
the learners are recipients of knowledge (the assumption is that the teacher/instructional designer has all the relevant knowledge);
from time to time the teacher/instructional designer will incorporate new ideas into the course to avoid the course becoming outdated;
this model is adequate for courses where the learners get into a new field and therefore might have little to contribute; and
this practice falls within the "gift wrapping approach" (and the quality is solely determined by the knowledge of the teacher/instructional designer and her/his ability to present this knowledge effectively
In contrast, the "courses as seeds" is build upon the following characteristics:
a course is considered as a seed, is offered to a community of practice which is interested in learning new material but many of the course participants are knowledgeable people in their own working environments;
the learners are not just passive recipients of knowledge, but become from time to time active contributors; and
therefore: at the end of the course, the content of the course will be greatly enriched through a semester-long interaction of knowledgeable people and important and relevant addition will be incorporated into the course before it is taught the next time
The value added by the "courses as seeds" approach is:
it is a model for learning in a knowledge society which is built upon distributed cognition, peer-to-peer learning, articulated learners, and enhancement of communities of practice; it is important for students to gain experience in such processes;
such an approach is a necessity for many domains and aspects of lifelong learning where communities of practice engage in the incremental construction of knowledge facilitated by a teacher;
it transcends the "gift-wrapping" approach by exploiting unique aspects of computational and communication media; and
although it shares objectives with other approaches such as CSILE by "reframing class discourse to support knowledge building in ways extensible to out-of-school knowledge advancing enterprises", it transcends CSILE in the following ways: (1) new knowledge contributed can employ a greater variety of conceptual structures (e.g., simulations, critiquing rules, partial designs), (2) retrieval is more broadly supported (for example: using artifacts as queries and using Latent Semantic Indexing, and (3) in CSILE, learners are learning mainly academic contents, not deepening their knowledge of a field of working expertise.
Course on Computer-Supported Collaborative Learning
The course on Computer Supported Collaborative Learning was organized by visiting professor Tim Koschmann. In the course, we developed a conceptual framework for collaborative learning based on readings from primary sources in the CSCL literature. Collaborative learning takes place within a group when learning takes place through the efforts of multiple group members interacting with each other. It can be distinguished from instruction in which knowledge is transmitted from a teacher to students and from cooperation in which tasks are divided up and individuals then share what they have learned individually. When viewed at a group or social level of analysis, it is clear that all learning is socially mediated: When learning, people rely upon shared language and thought practices. Most learning is motivated by the organizational setting in which issues arise, information is made available and confirmations are offered. The different conceptions of learning have different implications for computer support and the course reviewed the major categories of educational software that are available.
The course also incorporated an experiment in organizational memories for organizational learning by using a DynaSites discussion forum called DynaClass, developed as part of the OMOL Project. The use of this software was reflected upon almost weekly and it evolved accordingly. At first, the forum was used as a place for individuals to post their summaries of readings. Gradually, it became more of an exchange of ideas and responses. Eventually, the discussions on the forum were introduced more and more into the classroom discourse. In the end, the web-based forum was viewed in the class and was used to focus and structure in-class discussions.
Evaluation of CSCL Activity - SimRocket
SimRocket is a computer simulation that we developed in a collaborative effort to fit into the Mission to Mars curriculum developed at the University of Vanderbilt. It is built in the Agentsheets simulation environment developed at L3D and compiled into a Java applet. We tested it in a 6th grade classroom at a local Boulder school as part of a project-based curriculum.
Our classroom intervention was a study of collaborative learning. We wanted to see if the simulation would facilitate or mediate a process of collaborative learning within a group of 5 students working together. The study proceeded through the following steps and was videotaped for subsequent analysis:
The students were guided in a discussion of fundamental concepts related to their project of building a model rocket: thrust, friction, gravity, the use of a simulation model, experimental method.
The simulation was explained to the students. The simulation includes eight rockets with different parameters. The parameters determine how high the rocket will fly, although there is some noise so that each flight goes to a somewhat different height.
The students fired the simulation using seven of the rockets. Each rocket was fired 6 times by each of the two subgroups of students. The students recorded the height of each firing. The two subgroups shared their data and computed average heights for each rocket.
The students worked together to compute the effects of each parameter (engine, fins, nose cone, surface texture) on the average height. Using these results, they predicted the height of the 8th rocket.
The students fired the 8th rocket 12 times and found that its average height was very close to what they predicted.
The videotape of the SimRocket experiment was analyzed in the CSCL class as an example of collaborative learning. Analysis centered on the extent to which the group of students understood the experimental principle of varying one parameter at a time to determine its effect. An interesting interaction was noted between how well certain individuals could articulate this principle and how well the group as a whole understood it, as seen in their ability to correct member statements and to work together to predict rocket 8. SimRocket is available at http://GerryStahl.net/SimRocket
For more information on the CSCL class and to review the contents of the discussion forum visit http://www.cs.colorado.edu/~l3d/courses/CSCI7782-3-S98/.
Course on Designing the Information Society of the Next Millennium
For the second time, we offered a cross-disciplinary, graduate, undergraduate future-oriented course in which we explored the following themes of our research proposal:
Learning societies where lifelong learning is a fundamental activity.
Technological innovation in information and communications and effects of these innovations on our society and work practices.
Design in physical spaces (e.g., cities) and in information spaces (e.g., software) and the relationship between them; and how the space design may affect virtual communities of practice.
Evolution, design and sustainability, descriptive and prescriptive elements in design, and the role of breakdowns and symmetry of ignorance.
The course participants used a discussion forum to store organizational memory, and reflected on the effectiveness of the forum as an OM.
For more information visit http://www.cs.colorado.edu/~l3d/courses/CSCI4830-F97/home.html.
Philosophy of Undergraduate Research Apprenticeship Program
Apprenticeship learning in educational theory and practice has been offered as an antidote to the problems associated with conventional methods of instruction utilized in formal educational settings. In professional education, methods such as Problem-Based Learning have taken this philosophy to heart. Some aspects of research conducted at the graduate level also resemble apprenticeship learning. In undergraduate education, however, there are few opportunities open to students to participate in this form of learning.
Apprenticeship learning is "personal, hands-on, and experiential". Unlike most formal educational activities, apprenticeships are conducted in the context of some form of real work. Carpentry apprentices learn (at least in part) by working alongside more experienced carpenters at a building site. One benefit of this type of learning is that "the learning is meaningful because it is always related to what the learner is doing, trying to do, or trying to understand". Consequently, there is no reason to have its relevance pointed out or taken on trust.
By learning in the process of doing the apprentice learns not only the skills of a craft, but also "the premises on which its practice is based". The apprentice is not only learning an isolated set of skills, but is also acquiring a new social identity. In so doing, the apprentice acquires a new language, new "'ways of knowing' and 'learning to see'" and becomes a member of a community of practice.
Carpentry, for example, might constitute an example of a community of practice. It includes a community of participants with a specialized set of skills and tools. A particular project, however, such as the building of a house may bring together members of a variety of different communities of practice (e.g., electricians, plumbers). The process by which one gains entry into a community of practice is apprenticeship.
As learners undergo the transformation from novice to expert within a community of practice, they do not begin with the most skilled and difficult tasks, but instead begin with tasks that are appropriate to their skills and experience. The apprentice's contribution to the joint-activity is legitimate in that it is a part of ongoing real work as opposed to a school exercise. Their participation is peripheral in that the most skilled parts of the work are performed by more experienced members of the community. As apprentices acquire experience, however, they assume a more central role in the work of the community. Such a model calls for a re-evaluation of what it means to know and to learn.
Studies of Evolving Repositories
We prepared a paper on self-directed learning in which we explored Web-based evolving object repositories. While the paper focused on self-directed learning our conclusions from examining these repositories are applicable to organization learning processes.
Web-based evolving object repositories are an emerging concept in which communities contribute toward the creation of information spaces. These spaces can be reused by all members of the community for the creation of new environments. After having examined some object repositories, we have concluded that domain-oriented design environments can serve as models for these economies, that a software reuse perspective provides us with insights into the challenges these developments face, and that creation and evolution of them is best understood as a problem in learning.
The long term goal of an economy of knowledge is thwarted by an inherent design conflict: to be useful, an economy must provide many building blocks, but when many building blocks are available, finding and choosing an appropriate one becomes a difficult problem. Based on our investigations as well as others, we are convinced that to make an economy of educational knowledge a success, substantially more is required than creating objects and depositing them in a globally accessible information repository. Figure 7 illustrates three essential processes as they occur in using an economy of domain knowledge: location, comprehension, and modification (http://www.cs.colorado.edu/~gerhard/papers/se91). Providing support for organizational learning activities of organizational members must go beyond the capabilities of current object databases.
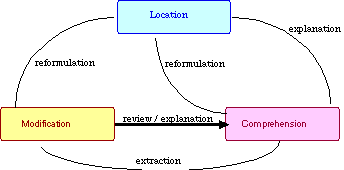
Figure 7: A Conceptual Framework for Reuse
Based on our examination of two object repositories (Gamelan and Educational Object Economy) and our experiences with others and our own (Behavior Exchange), we have formulated some guidelines for the development of an organizational memory that supports organizational learning in the conceptual framework for reuse presented in Figure 7. In Table 2, we present a comparison of the features of our proposed OMOL system to Gamelan and Educational Object Economy. Based on these comparisons, we developed some recommendations for creating OMOL systems. In summary, we argue for an OMOL system that integrates DODE functionality; supports seeding, evolutionary growth and reseeding of an organizational memory; and supports location, comprehension and modification cycle shown in Figure 7.
Table 2: Comparison of Object Economies Supporting Communities of Practice
| Gamelan | Educational Object Economy | Recommendations for OMOL System | |
| Scope of Coverage | Encyclopedic-indexes any resource related to Java technology | Wide-stores Java resources with educational uses | Domain specific pieces classified in appropriate framework for the given domain. |
| Target Users | Java developers | Educators / software developers | Individuals interested in a given domain |
| Content Providers ("Teachers") | Java developers | Software developers and educators | Members of the design community |
| Content Recipients ("Learners") | Java developers | Students (who receive content from teachers) | Members of the design community |
| When is Content Generated? | Design Time-contributors submit fixed resources. Self-contained (completely planned) pieces are regarded favorably as "complete." | Design Time-current objects are "finished products" by the time they reach repository users. Many objects cannot be modified. | Design Time / Use Time-Systems are built to be extended. Components evolve as system evolves. |
| Types of Artifacts | Incorporates any relevant information-commercial tools, complete Java applets, reusable software components, tutorials, etc. | Most resources are complete educational applets. Reusable components exist but are less common. | Many levels of granularity, fined-grained pieces, component libraries, and complete examples that provide multiple levels for modification |
| Mechanisms for Locating Information | Browsing-all tools are placed somewhere in a large,
strictly hierarchical space. Some items are cross referenced. Categories are maintained by
system administrators. Searching-component descriptions (abstracts created by authors) may be searched by keyword. Search criteria may not be refined. |
Browsing-one level of categories (sorted by educational
discipline.) Large number of resources returned at once. Searching-Numerous search criteria based on "meta-data," author, subject area, description keywords, and submission date. Reviews of resources may not be searched. Meta-data are currently not extensible. |
Browsing-multiple domain-specific hierarchies for
different user models (i.e., educators subject view or developers component view) Searching-combine formal (machine derived) information like usage information, code relationships, language keywords with informal information such as description and discussion. Use techniques to activate related knowledge. |
| Mechanisms for Comprehending Information | Gamelan staff may annotate resources with informative labels. Small amount of resource-related data stored in the system. Usage demonstrations must be provided by contributors. | Meta-data presented for all objects. Some meta-data may be used for further sort results, but only some filters are supported. Small amount of resource-related data stored in the system. Usage demonstrations must be provided by contributors. | Informal and formal data presented in a perspective appropriate for the user. Large amounts of design information available in the system. Interactive environments may provide demonstration of usage. Community may annotate artifacts with discussion. |
| Mechanisms for Modifying Information | None. Modification history of resources not captured by the system. | None. Modification history of objects not captured by the system. | Domain-specific environments may aid modification. Modification history tracked to aid developers and provide historical perspective of design decisions. |
To review the article visit http://www-jime.open.ac.uk/98/fischer/fischer-t.html.
Book on Domain-Oriented Design Environments
One of the goals of the OMOL project is to use the lessons learned from our creation and development in L3D of single simultaneous user, domain-oriented design environments (DODEs) to develop organizational DODEs focused on communities of practice. Here is a brief description of the milestones in our work with DODEs - summarized from our reflections while preparing the DODEs book.
At L3D, we developed our first DODE for kitchen design - Janus. Janus provided support for an individual kitchen designer. When building Janus, we thought about loading in "domain knowledge" in the form of rules of thumb and design rationale for what we thought of as a subdomain of residential architectural design. We assumed we could find such knowledge in books about kitchen design and by interviewing individual designers. Initially, we conceptualized this domain knowledge as being totally divorced from any community of practitioners, except in the abstract sense of all kitchen designers who exist. Any community-specific knowledge was accumulated in the catalog of designs in Janus, to the extent that one assumed that a community of kitchen designers would all use Janus on the same machine or that the catalog would somehow be distributed and updated on all their machines.
Then, our thoughts shifted when we started focusing on end-user modification and evolution. Our end-user modifiable version of Janus marked an important step in our conceptualization of DODEs. We allowed users to modify palette items and critics. Consequently, we supported the incorporation of community specific knowledge created by the community of users. However, under this model, our users simply updated the information to reflect changes in the generic domain of kitchen design (e.g., new appliances such as microwaves could be incorporated in the kitchens).
We took end-user modifiability one-step further in a new version of Janus - Hermes. We afforded the user community the opportunity to create 1) their own domain terms; 2) their own critics, searches and graphical palette items using these terms; and 3) graphical palette items and hypertext design rationale. Furthermore, we added perspectives functionality. Using the perspectives function, individuals, subgroups and communities could structure their own versions of all the knowledge. Despite this potential support for community-specific knowledge, with Hermes we mostly focused on individual designers.
With the lessons learned from our kitchen design DODEs, we developed systems to support specific communities of practice. Our first effort at this was the Voice Dialogue Design Environment - a system that supported a community of designers and had sets of critics representing different communities. Then, we developed the Evolving Artifact Approach system, which supported a specific community of practice, capturing the history of that community's design work on a specific project.
Our challenge now for developing an OMOL is to merge the architectures of DODEs with mechanisms for archiving and delivering community-specific knowledge. We want to provide adequate contextualized community-knowledge capture and delivery mechanisms, and to engage a user community in the adoption of a computational OMOL system.
In order to understand the work of others trying to support OMOL, we have been analyzing literature on organizational memory, organizational learning, computer support of collaborative learning, and related topics. In the process of researching the existing literature, we have been developing a categorization scheme for this field. Because our understanding has and will evolve as we learn from our readings and the implementations of our own systems, we are using DynaSources (described in the next section of the report) to store and deliberate over our findings. As such, DynaSources offers the members of our CoP - OMOL researchers - a forum for computationally mediated discussions and negotiation. We are currently considering extending the functionality of DynaSites, and all its separate utilities, to support active delivery by a computational agent of organizational memory in a non-intrusive and contextualized way and integrating DynaSources into a word processor. The current classification scheme of our readings categorizes them into literature pertaining to Self-Regulated Learning, Organizational Learning, Activity Theory and Intentional Learning. As our classification scheme evolves, members of our group can easily modify DynaSources to reflect changes in our conceptions and understanding.
Part II: Computational Support
The goals we outlined in our proposal are broadly to use the lessons we learned from the single simultaneous user DODE to develop organizational DODEs focused on communities of practice. Specifically, we intended to develop computation methods (a) to make the cost of contributing to OM low or nothing, and payoff high, (b) to allow the OM to be dynamically extended and updated, and (c) to make stored info relevant to task at hand. In Table 3, we show how we approached these goals with our software prototypes.
Table 3: How Our Prototypes Were Used to Achieve OMOL Project Goals
Prototype |
Lower Cost of Contribution |
Support Dynamic Evolution |
Make Stored Information Relevant to Task at Hand |
| WebNet | Integrate semantic objects into the OM and support work practices with planning and communication tools. | Allow users to create their own objects. | Support critiquing with argumentation. |
| DynaSites | Integrate different communication tools to support discussions (e.g., DynaGloss, DynaSources, VirtualLibrary, LinkClipBoard…) | Make modification of personal and public spaces possible for users without any programming experience. | Support annotations with links. Automatically notify users of changes to the organizational memory. |
| GIMMeMore | Capture email and usage data automatically (i.e., capture requires no additional effort by user). | Capture user-generated data. | Use LSA, to support natural language query. Visually informs user of information decay. |
| Mediator | Capture usage data automatically (i.e., capture requires no additional effort by user). | Allow user to change the criteria and type of usage data collected. | Develop separate UDA tools for specific uses. |
| ScrapWeb | Integrate tool into existing products. | Allow user to specify criteria and control information added to space. | Provide query tools. |
| WebGuide | Facilitate communication by computationally mediating discussions, and supporting the development of perspectives and processes of negotiation. | Allow user to create own views of information. | Store multiple perspectives. |
In summary, we used the following: 1) capture and processing of usage data, 2) data structures and interface support for negotiation and intertwining of perspectives, 3) interconnected information spaces, 4) latent semantic analysis for information retrieval, 5) scripts to integrate existing products to support personal information management,
In addition, based on our observations of social practices in CoPs and our examination of computational organizational memories such as discussion forums and object repositories, we propose to investigate in our future software prototype development efforts 1) the support of non-hierarchical discussion and design activities and their visual representation as directed acyclical graphs, 2) latent semantic analysis to provide feedback, and 3) development of a JavaBean library to support rapid prototype development.
Following are descriptions of the main prototypes we worked on during Year I of the OMOL Project:
WebNet is a design environment supporting the design, maintenance and administration of local area computer networks. The current implementation of WebNet combines graphical design tools with tools to access information in large, dynamic, and distributed information sources. WebNet's information space includes network design knowledge on the World Wide Web, and an archive of electronic mail communication between network designers. Thus, WebNet serves not only as a tool and knowledge source for individual designers, but also as a communication medium for members of network design communities to store, share and retrieve information about network design generally and about particular network designs specifically.
WebNet was designed to allow network designers to extend and modify their system as they use it to do design. WebNet integrates several network design tools. The screen image, Figure 8, shows a gallery of network devices, a worksheet in which a network is configured, an explanation of a particular network device, and query results over an archive of e-mail messages.
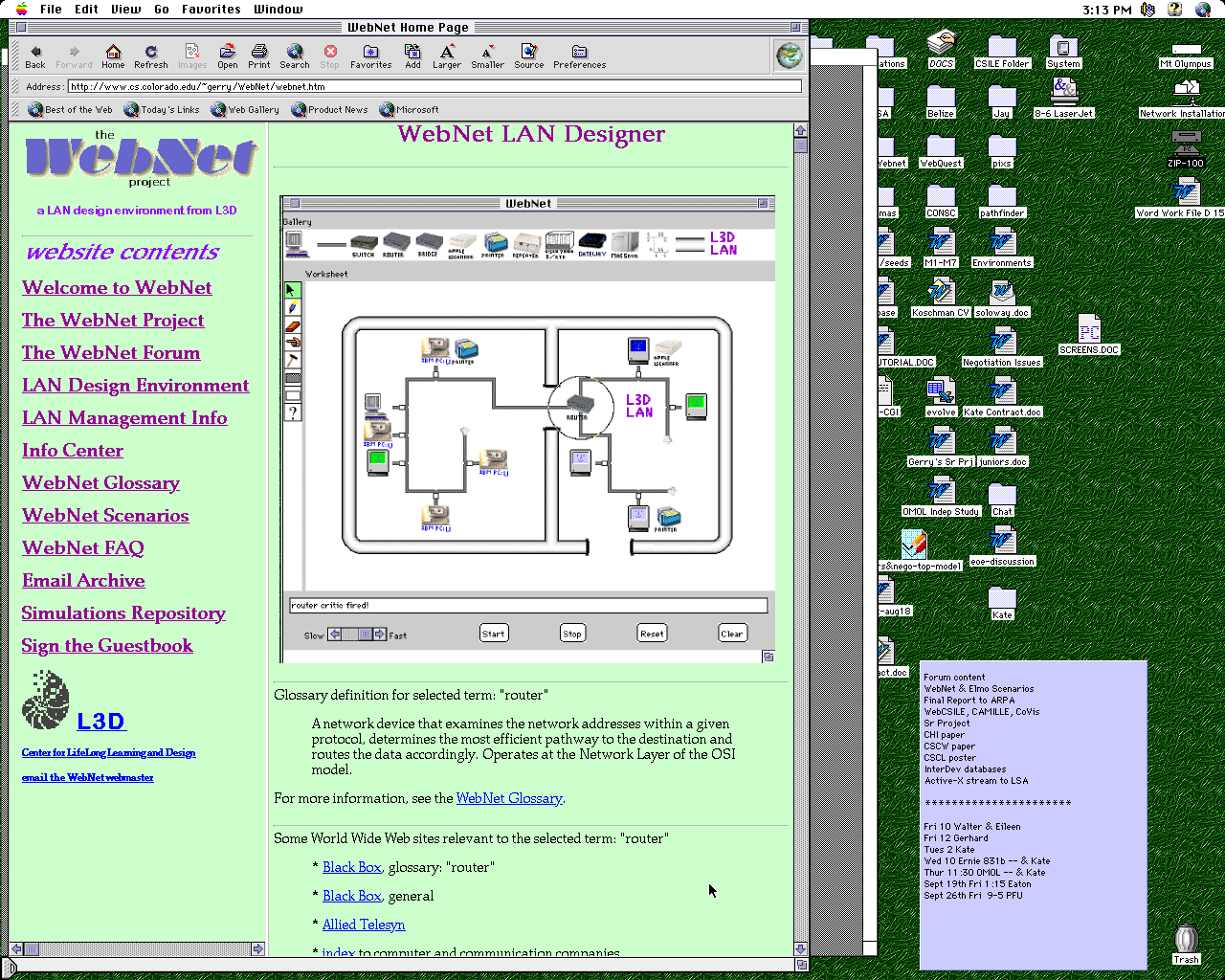
Figure 8: WebNet Home Page Showing WebNet Interface
The following is a scenario showing WebNet in use:
Delivering Web-based Information
Kay is a graduate student who works part-time to maintain her department’s LAN. The department has a budget to extend its network and has asked Kay to come up with a design. Kay brings up WebNet in her web browser at http://GerryStahl.net/WebNet/webnet.htm.
She opens up the design of her department’s current LAN in the LAN Design Environment, an Agentsheets simulation applet. Kay starts to add a new subnet. Noticing that there is no icon for an Iris graphics workstation in her palette, Kay selects the WebNet menu item for the Simulations Repository web page. This opens a web site that contains simulation agents that other Agentsheets users have programmed. WebNet opens the repository to display agents that are appropriate for WebNet simulations. Kay locates an agent that someone else has created with the behavior of an Iris workstation. She adds this to her palette and to her design.
When Kay runs the LAN simulation, WebNet proactively inserts a router (see Figure 8, upper right), and informs Kay that a router is needed at the intersection of the two subnets. WebNet displays some basic information about routers and suggests several web bookmarks with details about different routers from commercial vendors (see Figure 8, lower right). Here, WebNet has signaled a breakdown in Kay’s designing and provided easy access to sources of information for her to learn what she needs to know on demand. This information includes generic domain knowledge like definitions of technical terms, current equipment details like costs and community memory from related historical emails
WebNet
points to several email messages from Kay’s colleagues that discuss router issues and how they have been handled locally. The Email Archive includes all emails sent to Kay’s LAN management workgroup in the past. Relevant emails are retrieved and ordered by the Email Archive software based on their semantic relatedness to a query. In Kay’s situation, WebNet automatically generates a query describing the simulation context, particularly the need for a router. The repository can also be browsed, using a hierarchy of categories developed by the user community.Kay reviews the email to find out which routers are preferred by her colleagues. Then she looks up the latest specs, options and costs on the web pages of router suppliers. Kay adds the router she wants to the simulation and re-runs the simulation to check it. She saves her new design in a catalog of local LAN layouts. Then she sends an email message to her co-workers telling them to take a look at the new design in WebNet’s catalog. She also asks Jay, her mentor at Network Services, to check her work.
Jay studies Kay’s design in his web browser. He realizes that the Iris computer that Kay has added is powerful enough to perform the routing function itself. He knows that this knowledge has to be added to the simulation in order to make this option obvious to novices like Kay when they work in the simulation. Agentsheets includes an end-user programming language that allows Jay to reprogram the Iris workstation agent. To see how other people have programmed similar functionality, Jay finds a server agent on the Simulations Repository and looks at its program. He adapts it to modify the behavior of the Iris agent and stores this agent back on the repository. Then he redefines the router critic rule in the simulation. He also sends Kay an email describing the advantages of doing the routing in software on the Iris; WebNet may make this email available to people in situations like Kay’s in the future.
When he is finished, Jay tests his changes by going through the process that Kay followed. This time, the definition of router supplied by WebNet catches his eye. He realizes that this definition could also include knowledge about the option of performing routing in workstation software. The definitions that WebNet provides are stored in an interactive glossary. Jay goes to the WebNet glossary entry for "router" and clicks on the "Edit Definition" button. He adds a sentence to the existing definition, noting that routing can sometimes be performed by server software. He saves this definition and then clicks on "Make Annotations". This lets him add a comment suggesting that readers look at the simulation he has just modified for an example of software routing. Other community members may add their own comments, expressing their views of the pros and cons of this approach. Any glossary user can quickly review the history of definitions and comments–as well as contribute their own thoughts.
It is now two years later. Kay has graduated and been replaced by Bea. The subnet that Kay had added crashed last night due to print queue problems. Bea uses the LAN Management Information component of WebNet to trace back through the history of problems and changes leading up to the print queue problem.
The LAN Management Information component of WebNet consists of four integrated information sources: a Trouble Queue of reported problems, a Host Table listing device configurations, a LAN Diary detailing chronological modifications to the LAN and a Technical Glossary defining local hardware names and aliases. These four sources are accessed through a common interface that provides for interactivity and linking of related items.
The particular problem that Bea is working on was submitted to her through the Trouble Queue; her solution will be added there to provide documentation. Bea starts her investigation with the Host Table, reviewing how the printer, routers and servers have been configured. This information includes links to LAN Diary entries dating back to Kay’s work and providing the rationale for how decisions were made by the various people who managed the LAN. Bea also searches the Trouble Queue for incidents involving the print queue and related device configurations. Many of the relevant entries in the four sources are linked together, providing paths to guide Bea on an insightful path through the community history. After successfully debugging the problem using the community memory stored in WebNet, Bea documents the solution by making entries and new cross links in the LAN Management Information sources.
In this scenario, Kay, Jay and Bea have used WebNet as a design, communication and memory system to support both their immediate tasks and the future work of their community.
DynaSites is an application for creating interactive and evolvable web sites. Information spaces created using DynaSites are similar to threaded discussions and electronic conferencing systems in that they allow users to communicate directly and by doing so evolve a shared information space. DynaSites information spaces differ from threaded discussions in that they support the collaborative creation and evolution of artifacts through which communication can take place, rather than supporting communication as an end in itself. To learn more about DynaSites and to use it visit http://Seed.cs.colorado.edu/dynasites.documentation.fcgi$node=dynasites.doc.home.
DynaSites is intended to be used by webmasters (those who know about the web as a technology), in collaboration with users (those who use the web as a medium, but who may not understand the technology), to create an information space seed (a collection of information that is intended to evolve). This initial seed is then evolved directly by the user community. When creating the seed, the community does not need technical knowledge of the web or a webmaster to serve as an intermediary.
Each of the individual DynaSites, as well as the underlying substrate, are part of a research agenda aiming to transform the web from a broadcast medium (in which there are few producers and many consumers of information) to a knowledge construction medium (in which a community of users create, share, use, improve, and combine computational artifacts). This metaphor of collaborative knowledge construction is part of a larger vision of computational support for communities of practice.
Most sites on the web today are implemented as HTML files which are displayed in a web browser, such as Netscape Navigator. This model is well-suited for announcing information over the web. However, evolvable web-based information spaces are difficult to implement because they require source files to be modifiable by users. Not only does this require HTML knowledge and access to the source files, but it also poses security risks from trouble makers as well as from users who might inadvertently alter important information.
DynaSites implements a different model of web based information spaces. Rather than storing information in files, DynaSites stores information content and hypertext links as small pieces in a database. Pieces from the database are then put together by a program to create HTML pages. This model provides new possibilities for users to evolve the information they see in their browser. Users can add to the information space using forms that require no HTML knowledge.
DynaSites is implemented with the Frontier environment. Frontier provides a database, a scripting language, and many nice tools for building dynamic web sites. DynaSites uses the CGI interface to communicate with the web server. DynaSites documents push the CGI scripting paradigm to create dynamic page elements such as collapsible hierarchies, and richly annotated and interlinked documents.
The types of information that can be displayed in DynaSites include discussions, bookmarks, references, glossaries, and links. These various information types can be stored in different parts of DynaSites - DynaGloss, DynaBabyl, DynaClass, VirtualLibrary and DynaSources. DynaSites supports cross document integration. This means that a definition presented in DynaGloss can be referenced in a DynaBabyl discussion forum type posting, or a posting in one thread can be linked to a discussion in another. The linking options are limitless. See Figure 9. In addition to the public DynaSite spaces, there are personal information spaces such as the link clipboard, and carrels in the VirtualLibrary.
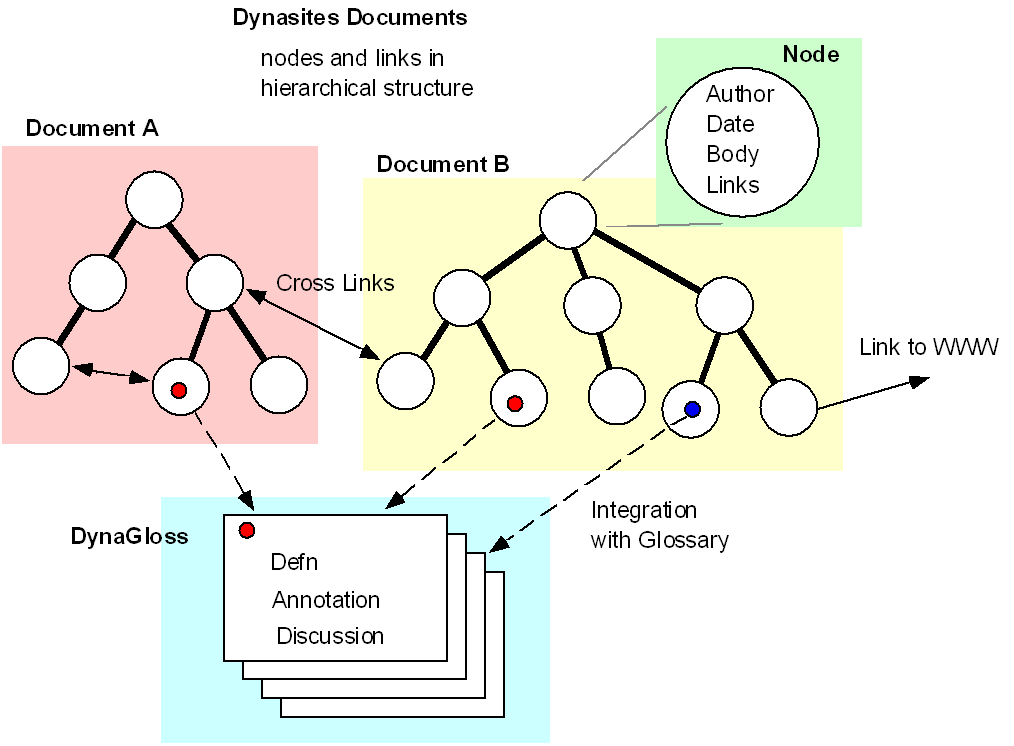
Figure 9: DynaSites Structure
DynaBabyl
DynaBabyl is a particular type of DynaSite. DynaBabyl is a set of functionality, originally developed to support discussion forum-type hyperdocuments. The DynaBabyl name comes from the ".babyl" file name suffix used by ZMAIL, Symbolic's fine email tool. The DynaBabyl substrate has evolved over time to contain tools for making and managing web-based information spaces. DynaBabyl documents can be connected to other DynaSite documents with the link clipboard function. Link clipboard let's you create links among DynaBabyl Documents and to the Web that can be attached to any DynaSite document.
DynaClass
DynaClass is an environment for class discussions. The prototype was created for the Spring98 CSCL (computer supported collaborative learning) class. DynaClass is modeled a bit on WebCSile. It is a bit simpler than DynaBabyl in structure, but offers more flexible functionality for creating and editing nodes (e.g., an automatic notification feature and typed nodes).
DynaGloss
DynaGloss is a new type of glossary in which terms are defined and debated by users. Anyone is free to define a new term, annotate an existing definition, or change the definition. DynaGloss supports the evolution of meanings, in an ongoing and collaborative fashion. All DynaSites documents can have links to the terms stored in DynaGloss. Currently, any terms in a DynaSites document that are placed in double quotes are automatically made into links to the DynaGloss definition of the term, if the term exists in DynaGloss. Figure 10 shows the index of this glossary (left), and the interface for viewing, annotating, and redefining the terms contained in the glossary (right).

Figure 10: DynaGloss Features
VirtualLibrary
The DynaSites VirtualLibrary prototype helps instructors and students collect, structure, and locate references to sites on the World Wide Web. Links to web sites are stored as elements in a database. Links can be created by anyone and added to the collective pool of links. Links consist of a URL (a web address), a title (determines the onscreen appearance of the link), keywords, and an annotation. The links stored in the Virtual Library can be searched. Currently there is a very simple searching mechanism that let's you find links by keyword and title.
The VirtualLibrary also includes carrels - personal spaces where each registered user of the VirtualLibrary may collect links and annotate them, and keep notes (as well as delete them). Within their Carrels, SuperUsers can create and manage reserves. Reserves are collections of links. An instructor, for example, might create a reserve for American Literature for storing links to Web sites describing important American authors. Once created, reserves are available to all users on the Reserve Desk Page.
DynaSources
An information space supporting the OMOL research group with the development of an OM of OMOL-related literature. In it, the members of the research group can store, annotate, and discuss research sources from the literature and the world wide web. The information space is queriable by title, author, contributor, or all DynaSources fields. When DynaSources is opened, the user is presented with a query tool, and a list of citation descriptions that he/she can scroll through (see Figure 11).
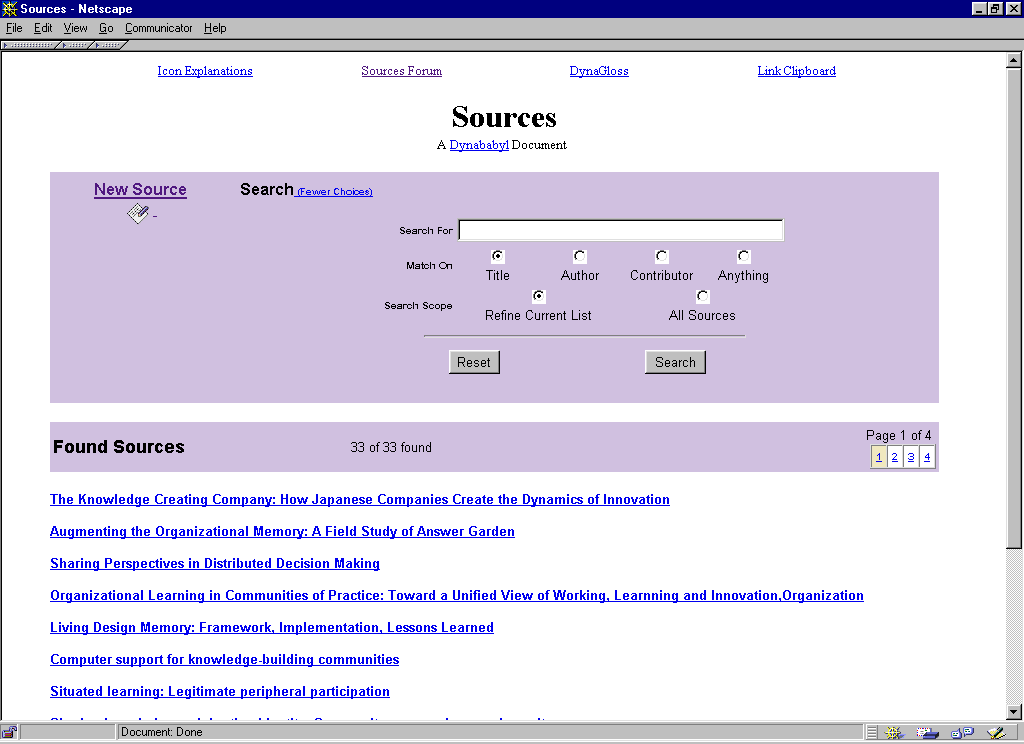
Figure 11: DynaSources Interface
Integration of DynaSites with Mr. Rogers
Mr. Rogers’ Sustainable Neighborhood, developed by undergraduate students over the course of the past two years, uses the WebQuest and Agentsheets mechanisms to create a neighborhood modeling environment, complete with various types of roads and housing, and other components such as parks, streetlights, shopping malls, restaurants, and parking lots (see Figure 12). A user plays the game as a bicyclist in the neighborhood, riding from landmark to landmark, where s/he is presented with a decision to make about the neighborhood.
During the first year of the OMOL project, we added support for discussions by addinging DynaSites to the Mr. Rogers environment. We also have server support for players of the game. Resources are now available on the WWW to inform the player about his or her possible choices in the game, their impact on sustainability, and link the player to the web pages of other communities facing similar choices. The integration of DynaSites into Mr. Rogers and the addition of a server to support the Mr. Rogers game can broaden support for collaboration among members of community by allowing temporal and location boundaries to be transcended.
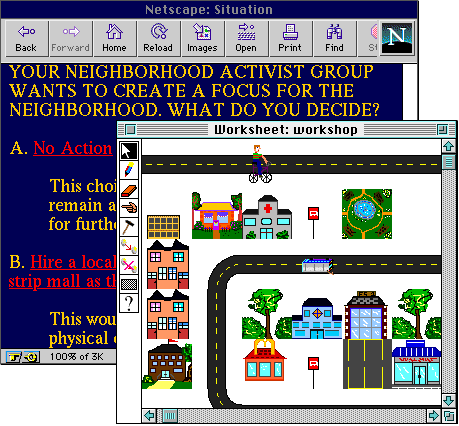
Figure 12: Mr. Rogers' Sustainable Neighborhood.
GIMMeMore is the second version of the GIMMe (Group Interactive Memory Management Environment) system. The original GIMMe system automatically captured group email in a commonly accessible repository, where it could be searched (using LSA) as well as browsed and restructured. GIMMe was implemented using Perl. GIMMeMore uses a different implementation approach in which many individual applications are bundled together into a "high tech toolbelt" (Sumner1995). GIMMeMore extends GIMMe in the following ways:
1) It handles information types beyond email messages, such as attachments and html.
2) It supports information decay, in which the appearance of information changes over time to indicate age.
3) It records usage data (who has visited what information, how many times a piece of information has been visited, etc).
4) It allows users to make "summaries" in which different pieces of information can be collected and annotated by users.
5) It tightly integrates query and browsing interfaces (addressing a major limitation of GIMMe).
6) Enables database queries in addition to free-text LSA queries to enhance searching of the information space.
The individual applications that comprise the GIMMeMore "tool-belt" (see Figure 13) are coordinated by the frontier system. Email is captured from a mailserver using Eudora. Frontier then extracts email from Eudora, and loads the messages into a Filemaker Database. Email attachments are processed by Frontier and stored as files which are indexed by the database. Users interact with GIMMeMore via a web browser (e.g., Netscape) using webpages created by the Tango environment. Requests for data are passed from the Browser to Tango to Frontier, which then executes the requests (with the help of the FileMaker database) and returns the results to Tango, which then creates new pages for the user.
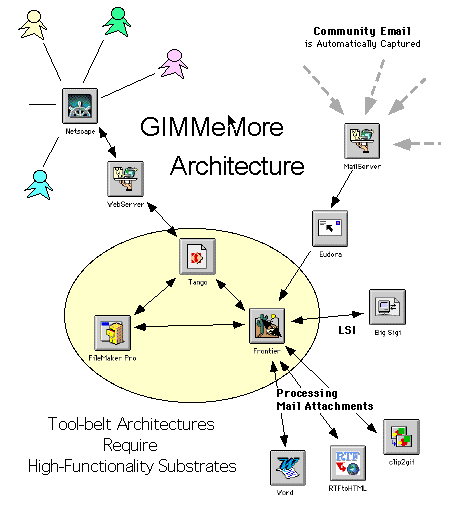
Figure 13: GIMMeMore Architecture
Mediator is a framework of OM utilizing usage data. Mediator keeps usage data of how objects are used and changed through processes of individuals' problem solving. Collective usage data of members of a CoP could show how members of the CoP solve a problem. Then a newcomer or a member who needs to know how to solve a similar problem or the same problem can use the usage data as a guide to solve the problem.
Each member of a CoP has Mediator and public information spaces for the CoP also has Mediator. All Mediators in the CoP form an OM. Mediator embedded to an individual’s working space captures usage data resulting from that individual's activities in solving problems. Mediator can also collect usage data from all the individuals' working spaces and construct collective usage data. Mediator of the public information spaces often collects usage data. Types of usage data and ways to collect and construct collective data are defined by the environment designers of Mediator, who make the system efficient for a CoP.
Environment Use
Mediator can adopt different kinds of Usage data aware (UDA) tools for different tasks done by members of the CoP. UDA tools help the users by suggesting activities that other members did. The suggestions are something such as, "if you are interested in this object then others who were interested in the same object have shown interest in these other objects." Such suggestions are inferred from the collective usage data and the users' activities taken in the tools.
UDA tools are transparent in terms of criteria and reasoning of suggestions. Therefore, users of UDA tools can investigate how a suggestion is made and modify criteria for other suggestions. Environment designers also use Mediator to improve OM. The designers can modify the collective usage data so that Mediator can provide more relevant suggestions by utilizing it. They also modify OM by reflecting on analyses of how members of CoP are using OM from the usage data. Also they can improve UDA tools by modifying the types of usage data to be captured and utilized and ways of
using usage data.
Prototype
A limited version of a UDA web browser was implemented to prototype mediator. The prototype was created with these existing software products: Frontier [Userland 1998], HTTP server, MacOS, HotSource [MCF and HotSource 1997], and Meta Content File (MCF) [Guha and Bray 1997]. The prototype’s module architecture is shown in Figure 14. All these products were integrated to create the prototype using MacOS AppleEvents.
Three features of Mediator are implemented in the prototype:
embedded usage data. The prototype uses HTML files as pieces of information. Each HTML file has associated usage data.
UDA tool. HotSource and HTML Browser were programmed to create the UDA browser. HotSource is used to display usage data for each file, and for communications between the ordinal web browser and HotSource. Through the communication mechanisms, the web browser and HotSource together work as a UDA browser.
distribution mechanism. In creating this feature, it was assumed that each member of the CoP and public information spaces have Mediator, and each fragment of OM that each Mediator has forms a larger OM for the CoP. Distribution mechanisms are a crucial part of the Mediator system. The prototype system uses the HTTP server and HTTP protocols for its distribution mechanism.
Figure 14: Module Architecture of the Mediator Prototype System
The process of usage data retrieval is shown in Figure 14. An information requester requests usage data for a particular file shown in the HTML Browser. The file shown is originally one of Information Provider’s files. A request of usage data is sent to the requester’s Frontier module (1) and Frontier sends a request to provider’s HTTP server (2). Provider routes the request to Frontier (3), retrieves requested usage data from Usage data database (DB) in Frontier, and returns it in the MCF format (4). The requester receives the MCF data (5) and routes the data to HotSource and displays it to the user (6). The user can display corresponding HTML documents while investigating the usage data in HotSource.
The most important implementation consideration of ScrapWeb is not to be intrusive to users’ routine task and to reduce the cognitive load needed by users to operate it.
As shown in Figure 15, ScrapWeb is implemented by integrating Eudora Pro, Netscape Navigator, Filmmaker Pro and Webstar with the scripting language and environment Frontier (Userland-Software-Inc., 1996) as a glue. Both Eudora and Netscape Navigator are designed to be interfaces to the Internet. They are good at gathering, and displaying information available on the Internet, but they have minimal functions to help users organize and manage the gathered information. On the other hand, database systems such as Filemaker Pro are good at organizing and managing information, but they do not have a direct interface to the Internet. ScrapWeb combines the complementary functions of these products in the Mac OS by making use of their scriptability, which means they can communicate with each other through Apple Events.
In ScrapWeb, Frontier is used as the glue to integrate Eudora, Netscape and Filemaker Pro. Extensions are made to both Eudora and Netscape Navigator to allow users to extract information. Frontier will feed the extracted information into the database Filemaker Pro to build personal information space for users. When users want to retrieve information from their personal information space, Frontier is activated from Netscape Navigator to deliver the information and display it in Netscape Navigator.
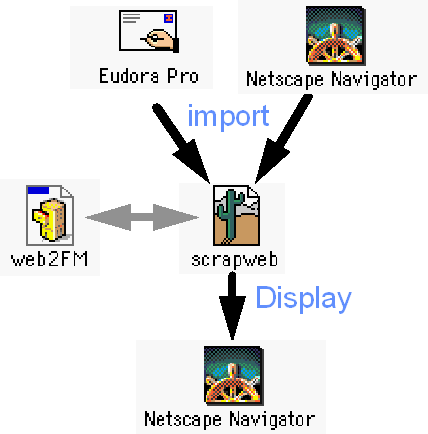
Figure 15: Architecture of ScrapWeb
Extensions to Netscape Navigation are made by adding new menu items. The menu items allow users to import the current URL into their personal information space as simply as when they add bookmarks. While importing a URL, users are able to give a name to the URL being stored. In addition to names and URLs, users are also able to fill in a Keywords field, which can be used for dynamic categorization, and Annotations to the URL, which can server as anchors for later retrieval. Keywords can be multiple and these keywords are used to reflect the various aspects of the contents of the saved URL. Annotations are free style text and they are used to capture users’ reflection on the current URL and these captured reflections enrich the indexical knowledge which, as a result, facilitate the effective recovery of information at later time. All these fields are searchable at the retrieval time.
Users do not have the same interest in all URLs in their personal information space. Consequently, a field to store the user's level of interest in the URL has been added to help users organize and retrieve the URLs in a more efficient way. A similar feature to this helps users store URLs which they have serendipitously encountered and are not of immediate benefit. ScrapWeb allows users to designate a rough plan such as "I may visit it 7 days later" together with the tracked URL. In addition to above information, ScrapWeb automatically insert a date field marking the day when the URL is stored. The text content of the URL is also downloaded simultaneously in case users want to retrieve a URL from the vague memory of parts of the contents. The saved contents are not meant to be displayed later; instead, they are only used as searchable objects to help users to locate the exact URL. When the found URL is displayed finally, it will still point to the original place. Figure 16 shows how the storing of URL works. Users issue a command from the menu bar of Netscape Navigator (or by a shortcut key) and fill in the forms, then all these information goes into users’ personal information space and users remain working in Netscape Navigator.
Email messages are saved into the ScrapWeb either in single email base or folder base. Dumping whole email folders into the ScrapWeb is useful for those users who subscribe to some email lists which mainly consist of informational notes. Users may not have enough time to go through all emails sent around in that list, but they keep all those or part of them for later consultation when they encounter with some problems to be solved.
Figure 16: Export A URL into ScrapWeb
Figure 17: Search URLs Interface
Recovering of information from the personal information space in ScrapWeb is directly launched from Netscape Navigator. This does not trouble users to switch windows back and forth. ScrapWeb allows users to search through their personal information spaces from different clues that they have in their mind. Names, URL address, keywords, words in annotations, words in content are all used as searching criteria. Even the date ranges or their reading plans can also be used as for searching. When users input the fragments of their memory into the searching interface of ScrapWeb, the system is able to create a set of bookmarks dynamically that reflects users’ current interest. These bookmarks could be rendered in different orders, such as the rank of interest, the date of saving, or the alphabetical order. According to the reading plan, users are also able to get today’s (or this week’s) reading list. Some frequently used searching can be encoded into the system and to be launched in one touch. Information associated with each items in the ScrapWeb may be modified at revisiting time and to be reflected in later use. Visiting history of each item is also captured automatically. Figure 17 is an example of retrieval interface and the bookmark list generated on-the-fly. Searching through the emails can be issued from both the Eudora window or the Netscape Navigator.
In late 1997 we decided to apply our vision of intertwining perspectives and negotiation (see section on "Support for Perspectives and Negotiation" under "Conceptual Frameworks", above) to a situation in middle school (6th grade, 12 year olds) classrooms we work with. The immediate presenting problem was that students could not keep track of web site URLs they found during their web research. The larger issue was how to support team projects. The more we discussed computer support for collaborative student web research, the more complicated and detailed the issues became. To facilitate our own collaboration we adopted two representations: (1) formal modeling of the software procedures, data elements, and social context; (2) design of a detailed user interface using HTML.
The result of our collaboration is an interface design for WebGuide, a web-based prototype that integrates perspective and negotiation mechanisms to support collaborative learning. To make our design concrete, we focused on a project-based curriculum on ancient civilizations of Latin America used at the school. The example of this student research project is well suited to illustrating the power of intertwining perspectives and negotiation: it shows the level of complexity that our approach can handle.
Sixth grade provides an exciting and challenging venue for this kind of software because the students are just starting to acquire adult cognitive skills and they are open to new experiences. The WebGuide system is designed to make explicit and scaffold for students the structure of web research, team collaboration, personal perspectives, and group negotiation that they may be experiencing for the first time in their lives.
WebGuide is a glorified web bookmark manager and electronic notebook application, enhanced with perspective and negotiation mechanisms as described below. Students can conduct web searches, collect, annotate, categorize, and organize bookmarks for sites they like. They can summarize or excerpt the web page contents (there is no need to copy the full contents because it is already available through the active bookmarks). Students are encouraged to use the facilities of WebGuide to make the results of their research more self-explanatory for themselves and their team mates by defining a hierarchy of headings or categories, arranging bookmarks under these, and adding concise summaries of the content or importance of the bookmarked sites.

Figure 18: Kay's Personal Perspective
Figure 18 shows a view of Kay's (a student) personal perspective in WebGuide. There are three topics visible in this view. Within each topic are short subheadings or comments, as well as web bookmarks and search queries. At the bottom is access to search engines.
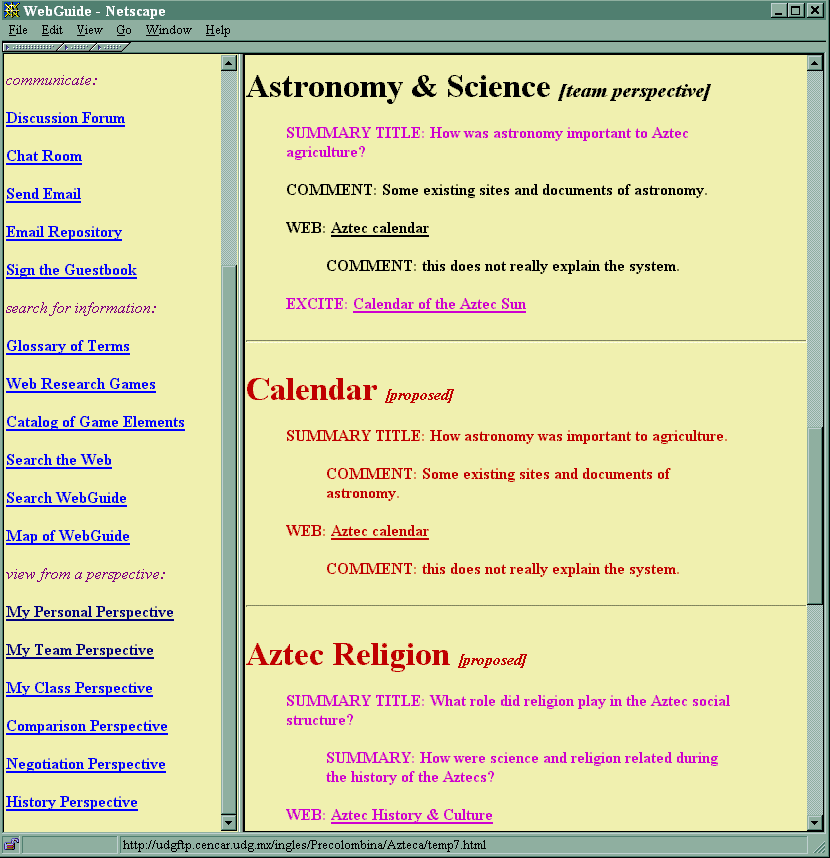
Figure 19: Negotiation Perspective
In compiling a list of requirements for WebGuide, we focused on how computer support can help structure the merging of individual results. Such support should begin early and continue throughout the research process. It should scaffold and facilitate the decision-making process so that students can learn how to build a consensus. WebGuide combines displays of individual work with the emerging group view. Note that the topic on Aztec Religion in Figure 19 has been proposed by other students to be part of the team perspective. The other two topics are ideas that Kay is preparing to work on herself. Within her electronic workspace she views information from the team perspective along with her own work.
Each student should be able to view the work of other team members as they work on it, not just when it is submitted to the team. Students should be able to adopt individual items from the work of other students into their own perspective, in order to start the collaboration and integration process. From early on, they should be able to make proposals for moving specific items from their personal perspective (or from the perspective of another) into the team perspective, which will eventually represent their team product, the integration of all their work.

Figure 20: Inheritance of Perspectives
WebGuide pages are structured by topic headings or categories for organizing the bookmarks and queries. These categories can initially be created without any bookmarks or queries as preparation for looking for relevant information, as Kay has done for the topics of Mexico City and Live Sacrifice (in Figure 18) that she intends to research. The categories can be structured hierarchically to create an information outline. Comments can optionally be attached to any information item. Every item is tagged with the name of the person who created or last modified it. Items are also labeled with perspective information. Furthermore, there is a set of functions which can be used to edit the information items.
Because of the hierarchical nature of items, something that appears as a unit of information that can be proposed for negotiation may actually consist of many parts, some of which appear differently in different students’ perspectives. The possibility of information items having a complex but hidden internal structure is required for the intertwining of perspectives and negotiation. The internal complexity is handled by the perspective and negotiation mechanisms behind the scenes of the WebGuide interface.
While fairly complicated manipulations may be going on behind the scenes, the interface attempts to present a relatively clean metaphor of perspectives and negotiation. Figure 17 shows a view of the WebGuide table of contents, which is always visible as a frame on the left. The table of contents lists communication media and information retrieval tools that are bundled into WebGuide. As part of this list of tools, the six perspectives that let students compile their individual and joint research are also listed:
The student’s personal perspective is their private work space.
The team perspective contains both items that have already been accepted by the team (like the Astronomy & Science topic in Figure 19) and items that are currently proposed for negotiation (the other topics in Figure 19).
The class perspective is created by the teacher to start each team off with some initial bookmarks and suggested topics.
The comparison perspective combines all the personal perspectives of team members and the team perspective, so that anyone can compare all the work that is going on.
The negotiation perspective contains all the information related to the current status of negotiation on an item proposed for the team perspective.
The history perspective is an archive of all information that has been entered in WebGuide. It is primarily for the teacher (or researchers), but can also be used by students to retrieve previous versions of items.
The power of the perspectives mechanism comes from the inheritance relations among these six different kinds of perspectives. Figure 20 shows these relations for the Aztec team and three of its members:
The team perspective is pivotal. It includes accepted and proposed items. It gradually collects the products of the whole process.
Each student’s personal perspective inherits a view of everything in the team perspective. The students can each modify (add, edit, delete) their virtual copies of team items in their personal perspectives. They can also create completely new material there.
The comparison perspective inherits from the personal, team, and class perspectives. Students can go here to get ideas and copy items into their own personal perspective or propose items for the team perspective.
The negotiation perspective inherits proposed items from the team perspective. When they are approved or rejected at the end of negotiation, then their status in the team perspective changes.
The history perspective inherits from the comparison perspective, that contains information from all the other perspectives.
Of course, there is not really such a multiplicity of information in the central database. The perspectives mechanism merely displays the information differently in the different perspectival web pages, in accordance with the relations of inheritance.
WebGuide is available at http://GerryStahl.net/WebGuide
Applying
WebGuide to GambleGulch Project
During the end of Year I we are initiating an effort to apply WebGuide to a geoscience project in a Denver middle school. Geoscientists of today and of the future are faced with a growing array of difficult multi-disciplinary problems. These problems require productive interaction between teams whose members represent different areas of scientific expertise and different segments of society with stakes in solving the problems. Each of these groups brings a different perspective to the table. One of the four goals of the National Science Education Standards is "to educate students who are able to engage intelligently in public discourse and debate about matters of scientific and technological concern." This requires understanding different perspectives and being able to evolve action plans based on that understanding. We will blend an award winning middle school science project with community mentors representing those perspectives in an innovative World Wide Web environment for doing just that.
The science project involves testing the effectiveness of several types of artificial wetlands in abating the negative chemical effects of drainage from an abandoned mine in the Rocky Mountains. Over the last five years students identified those effects and their source, researched methods for abating the effects, and participated in the design and construction of the artificial wetlands. They now have two years of data that are being used to demonstrate the positive results. They are ready to tackle the next obstacle: integrating those results into an action plan that considers the needs of the communities with stakes in that plan.
Students will form teams corresponding to each of these groups. They will research their team's perspective individually with guidance from the teacher and from representatives of those communities that have agreed to act as mentors. They will then bring together their individual results into a team perspective and the perspectives of all of the teams will be considered in the action plan. The teamwork processes required for these two phases is directly supported by the technology that we will use.
The technological framework is provided by WebGuide. This tool allows individuals to record and annotate their research into "perspectives". It then provides tools that support collaborative processes: proposing ideas, comparing and assessing ideas, negotiating, and reaching consensus. It provides an environment in which students can actually practice these processes, observe how to do them well, and improve their skills. It also allows the community mentors to directly observe and facilitate these processes from their offices or homes. This is fundamentally different than throwing a group of students into a room with instructions like "do a team project". It provides an electronic venue in which they learn how do to team projects.
Allowing Learners to be Articulate by Incorporating Automated Text Evaluation into Collaborative Software Environments
We developed the State the Essence software for supporting the construction of knowledge in classrooms. It provides a way of developing the articulate self-expression of individual learners without over-burdening teachers. Automated text evaluation mechanisms are used to replace fact-centered questions with open-ended, question-answer interactions, without requiring continuous teacher intervention. More generally, the project addresses how software environments can help students to learn in an information-intensive, technologically mediated world by matching individual competencies to appropriate resources.
State the Essence provides feedback to students constructing concise summaries of essays. It provides guidance and practice in the critical skill of summarization. We are assessing how the software improves student learning. We intend to sue this software to support collaborative learning in WebGuide. Students will be supported in summarizing their research findings for the organizational memory and in summarizing the results of organizational learning projects.
State the Essence uses latent semantic analysis, or LSA, to analyze text contents. LSA computes the semantic relations within a corpus of literature on a given subject matter and then uses this information to judge the semantic similarities among submitted written responses. We plan to incorporate LSA in a variety of ways within our educational software in order to explore a range of theoretical issues related to how computer-based media can help students learn.
We will develop several software prototypes with LSA mechanisms and evaluate them in the classroom. The software will be extended to allow students to design and create their own games for fellow students to play. Both questions and answers will be in text format, evaluated automatically by the software using LSA. Ultimately, LSA can be used to match the most appropriate versions of games or information sources on web sites to different classrooms or to individual students by evaluating the students' written products and comparing them to alternative sources of background information.
State the Essence is available at http://GerryStahl.net/Essence
In addition to the three PIs on the NSF grant, a dozen students and collaborators participated actively on the OMOL project during its first year.
Among the participants, three students completed degree programs:
Stefanie Lindstaedt - graduated in May with a Ph.D. degree. Her thesis focused on the development of organizational memories for communities of practice. She is now working in industry on an organizational memory project.
Taro Adachi - graduated in May with an M.S. degree. His thesis focused on usage data in support of organizational memories. He is now a visiting researcher in the OMOL project, from PFU, a Japanese company collaborating closely with the OMOL project.
Rogerio dePaula - will graduate in August with a M.S. degree. His thesis focuses on the structure of collaborative discussions within communities of practice. He will be entering the Computer Science Ph.D. program in the fall of 1998.
The OMOL project benefited from the collaboration of the following researchers from PFU and SRA, two Japanese software firms who are providing additional support for research at L3D on organizational memory: Taro Adachi, Yoshikazu Hayashi, Brent Reeves, Shigera Kurihara, Yunwen Ye.
Several visiting professors, supported by their home institutions, have participated in the OMOL project: Thomas Herrmann, Tim Koschmann, Frieder Nake, Masanori Sugimoto.
Four people have provided contracted services to the OMOL project:
Gabe Johnson, an undergraduate computer science major, is assisting in software development.
Kate Ingmundson, a graphic artist, designed the OMOL web site, posters, flyers and slides depicting OMOL research.
Barb Stuart, an authority on collaborative learning, started the OMOL Sources effort, a review of literature on organizational memory and organizational learning.
Jessica Witter, a researcher, worked on the preparation of this annual report and took over the OMOL Sources effort.
G Fischer. "Domain-Oriented Design Environments: Knowledge-Based Systems for the Real World", Special Issue on Successes and Pitfalls of Knowledge-Based Systems in Real-World Applications, International Journal "Failure & Lessons Learned in Information Technology Management", Vol. 1, No 2, 1997, pp. 123-133
G Fischer. "Computational Environments Supporting Creativity in the Context of Lifelong Learning and Design", (with Kumiyo Nakakoji), Special Issue of the International Journal "Knowledge-Based Systems," Elsevier Science B.V., Oxford, UK, 10, pp 21-28
G Fischer. "Lifelong Learning", NSF Symposium Proceedings on Learning and Intelligent Systems, 1997, pp 7-12
G Fischer. "Enhancing Communication, Facilitating Shared Understanding, and Creating Better Artifacts by Integrating Physical and Computational Media for Design" (with Ernesto Arias and Hal Eden), Proceedings of Designing Interactive Systems: Processes, Practices, Methods, and Techniques (DIS’97), ACM, New York, NY, pp 1-12
G Fischer. "Evolution of Complex Systems by Supporting Collaborating Communities of Practice", Proceedings of the International Conference on Computers in Education, Kuching, Malaysia, Association for the Advancement of Computing in Education (AACE), pp 9-17
G Fischer, E Scharff. "Journal Articles under Review: "Learning Technologies in Support of Self-Directed Learning", submitted to Journal of Interactive Media in Education
T Herrmann & G Stahl. "Verschrankung von Perspectiven durch Aushandlung." Accepted at Interaktion in Web: Innovative Kommunikationsformen, Marburg, Germany. Available at http://GerryStahl.net/HomePage/Publications/Verschrankung/Verschrankung.html. Translated by G Stahl as "The Sharing of Perspectives by Means of Negotiation." Available at http://GerryStahl.net/HomePage/Publications/Sharing/Sharing.html.
G Stahl. "Collaborative Information Environments for Innovative Communities of Practice." Accepted at DCSCW '98 (The German Computer-Supported Cooperative Work conference). Available at http://GerryStahl.net/HomePage/Publications/DCSCW/DCSCW.html.
G Stahl, G Fischer, J Ostwald. "Collaborative Information Environments for LifeLong Learning in Communities." Submitted to CSCW '98. Available at http://GerryStahl.net/HomePage/Publications/CSCW1/CSCW1.html.
G Stahl & T Herrmann. "Intertwining Perspectives and Negotiation." Submitted to CSCW '98. Available at http://GerryStahl.net/HomePage/Publications/CSCW2/CSCW2.html.
IBM Research Center, Adliswil, Switzerland: "Organizational Learning and Organizational Memories", Oct 30
University of Tuebingen, Department of Education, "Conceptual Frameworks and Innovative Computational Environments In Support of Self-Directed and Lifelong Learning", Oct 25
German Bundesministerium für Bildung, Wissenschaft, Forschung und Technologie: "Lifelong Learning, Creativity and Innovation", Oct 28
Information Technology Institute, Singapore, "Learning on Demand — Why Is It Necessary and Why Does It Make a Difference?", Nov 28
National University, Singapore, "Seeding, Evolutionary Growth, and Reseeding: Constructing, Capturing, and Evolving Knowledge in Domain-Oriented Design Environments" Nov 27
University of Sarawak, Kuching, Malaysia, "Evolution of Complex Systems by Supporting Collaborating Communities of Practice", Dec 2
NSF Symposium on Human-Centered Design, Washington DC, "Making Learning a Part of Life — Beyond the "Gift Wrapping" Approach of Technology", Nov 13
Faculty Teaching Excellence Program, CU Boulder, "Rethinking Education, Teaching, and Learning: Beyond the "Gift Wrapping" Approach of Technology", Sept 9