![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
|
|
|
|
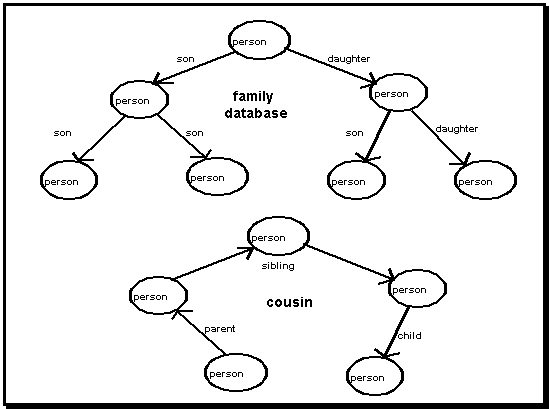
Appendix B. Tacit Usage of the Hermes LanguageThis Appendix is intended to give the flavor of the Hermes Language in use. It describes two small applications that were programmed during the early development of the languageand which actually drove the definition of much of its functionality. It also discusses four computational mechanisms that can be used within the language. In each example application or computational technique, there is a mixture of support for tacit and explicit understanding: * The example of family relations shows how a system of terminology can be defined in the Hermes language for expressing common family relations. However, while these terms may be easy to use once defined, even the definition of a basic term like brother or sister (sibling) can require a relatively high degree of explicit reflection. * The attempt to build a mini-expert-system to automate the job of an academic advisor using the Hermes language was instructive. On the one hand, building the application strained the ability of the language to construct complex procedures, requiring explicit programming strategies to be applied in an environment whose only support for that is abstraction. On the other hand, once defined, the application defined a micro-world in which users could browse and pose queries in ways not possible in closed expert systems. * The definition of Predicates as a subtle variation on Associations gives substantial extended power to the language in practice and at the same time nicely hides from the user some of the underlying complexity of definitions that stretch across multiple hypermedia links. * As programs in the language become more complex, issues of variable binding arise that may be confusing to think through. Hermes solves these issues in an intuitive way so that they ordinarily need not come to the attention of the user. * The use of recursive procedures to compute transitive closuresboth breadth-first and depth-firstgenerally requires cognitively burdensome abstract thinking. The Hermes language can support recursion through simple expressions. The problem of the recursive out is handled automatically by a natural convention having to do with hypermedia navigation. * Decision trees can be set up using hypertext links between nodes that contain conditions expressed in the Hermes language. The links between the nodes model the decision tree in a clear way. This supports the explicit understanding of the logic of the decision tree in an intuitive manner. * The options of the Hermes language support defeasible reasoning flexibly. They often eliminate the need to think through all the possibilities explicitly and allow the user to state in an understandable way the critical condition. Programming family relations. A textbook example from logic programming like Prolog provides a good illustration of how terms can be defined in the Hermes language to break down and solve a typical inference problem. The domain of family relations makes a nice test case because it is easy to compare the use of the Hermes language with ones tacit understanding of these relations and with the need in ordinary conversation to occasionally make these tacit understandings more explicit. Take the problem: given a network of people nodes linked by son and daughter links, infer cousin relationships. Inference is defined as the combining of facts to derive new facts. Here, facts about sons and daughters are combined to produce facts about who is a cousin of whom. This is a non-trivial task for humans, generally requiring people to consciously articulate part of the computation (e.g., "Let's see, her mother is my father's sister. . . .")
Figure A-1. Family relations. The definition of cousin from son and daughter links. In the Hermes language, the problem can be solved by the definition of the following terms: children: sons or daughters. parents: inverse sons or inverse daughters. siblings: children of parents that do not equal that (last subject), without duplicates. cousins: children of siblings of parents. Of course, these definitions require some explanations about the languagealthough probably less explanation than corresponding definitions in a traditional programming language like Lisp or Prolog. The children predicate includes nodes linked by both sons and daughters primitive links. Inverse links are primitive links traced backwards, like from the son back to the person whose son he is. The definition of siblings is inherently tricky. Most likely, the definer of this predicate would discover an adequate definition through a series of successive refinements. If one defines siblings as just children of parents, one discovers upon first use of the predicate that the original people are always included among their own siblings, because they are sons or daughters of their own parents. Therefore, a condition must be added to exclude the original person (i.e., the last subject, to whom the expression is applied) from the result list. Similarly, there will usually be duplicate names on the list of siblings because they are children of both the mother and the father of the original child. The simplest way of solving this problem while maintaining the ability to handle children of multiple marriages is to simply eliminate duplicates from the final list of results. The complexity of the definition of siblings is telling. Although the task of determining cousins is difficult for people, the problem does not lie in the definition of siblings but rather in the sequence of steps that must be put together. People naturally exclude the extra results that pop up surprisingly when the siblings term is incompletely defined. This is symptomatic of the fact that programming in any language in any domain is going to require some explicit steps of logical analysis and some efforts at debugging. No computer language can entirely avoid that. The primary advantage of the readability of the Hermes language is that once terms are successfully defined, it is clear what they mean, even for someone with little training in the language. The definition of siblings is about as obscure as any statement in the language need be. Given the above definitions, the following computations can now be evaluated: cousins of sandra people that have cousins and have less than 3 cousins, with those items Furthermore, these definitions have begun the creation of a domain language for family relationships. It is an easy matter to add predicates for brothers, aunts, grandparents, etc. The academic advising application. To test an early version of the Hermes language, an application was created using information about the curriculum of the College of Environmental Design at the University of Colorado. This information included not only lists of offered courses, but other facts and rules used by the College's official student advisor. Courses were linked to their prerequisites and to their categories, such as which curriculum they belonged to and which elective breadth requirements they satisfied. Other, less formal factors were also included, like which courses were particularly labor intensive. Primitive nodes and links were defined to correspond to information that students traditionally enter on forms prior to seeking counseling from the human academic advisor. This includes the students name, curriculum option, semester number, and courses taken in the past, taken currently, or proposed. The centerpiece of this application was the definition of a term named advice. The expression defining this term was built on a combination of several specific kinds of advice, which in turn used specially defined terms to compute inferences across the hypermedia. The idea was that a student, Sandra, could enter her name, curriculum option, semester number, completed courses, current courses and proposed courses into the hypermedia system (instead of onto a paper form). By clicking on the Advice button, Sandra would initiate the query, advice of sandra. The query critiques Sandra's proposed list of courses. This is a typical result:
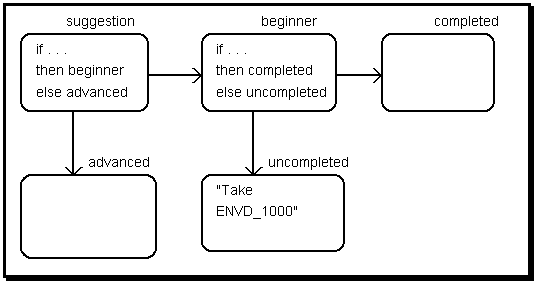
Here is some advice on your choice of courses: The following courses each require a lot of work. It would be wise not to take them in the same semester: ENVD 3220 Planning Studio 2 MATH 1300 Calculus The following courses are not designed for your curriculum option: ENVD 3220 Planning Studio 2 You have not taken the listed prerequisites for the proposed courses: ENVD 3220 Planning Studio 2 With your proposed courses you will not satisfy the following elective breadth requirements: science It would be wise to take a course in one of these areas rather than the following proposed courses in elective areas for which you have already satisfied the breadth requirements. FINE 1012 Art History Figure A-2. Output from the academic advising application. The above is the actual system output for a sample student. Computations have been performed to check, count, and list courses meeting or not meeting certain conditions. In particular, for instance, the advice about breadth requirements is only displayed if the proposed courses include an elective in an area that has already been satisfied and do not include one in an unsatisfied area. This kind of inferencing facilitates the offering of important information tailored to a particular user in a way that is impossible in a purely navigational hypermedia system. It begins to look like a rule-based expert system, but without many of the problems of such systems. To give a feel for the computations carried out by the language, the computation of prerequisite_problems will be detailed. The query, advice of sandra, makes use of a term, advice. This term is defined as follows: advice: advice_intro and labor_intensive_advice and option_advice and prerequisite_advice. In this way, the one term combines the terms for the four major computations in advice. The prerequisite_advice component is a term defined as follows: prerequisite_advice: prerequisite_intro and prerequi-site_problems if there are prerequisite_problems. This first checks to see if there are problems with prerequisites; if there are, it prints out a message and then lists the problem courses. The checking and listing is done with the following term: prerequisite_problems: proposed_courses that have prerequisites_not_taken. This term checks each of the students proposed courses, using the following term : prerequisites_not_taken: prerequisites that are not included in courses_taken. For each of the students proposed courses, this term follows each prerequisites link and then checks if the node for that prerequisite is in the set of nodes resulting from the query, courses_taken [of sandra]. If it is not, then the proposed course for which it is a prerequisite is returned. An example of this was seen in the advice output above, where ENVD 3220 is listed. Several problems can be noted in this implementation, if considered from a traditional computer science perspective: (i) First, there is a serious efficiency problem. (ii) Then, there is the complexity involved in setting up the application. (i) The efficiency problem is a result of the operator nature of the language. Many computations are done redundantly. For instance, in the prerequisite_advice computation the term prerequisite_problems is evaluated twice. Even worse, the subquery, courses_taken is evaluated many times, although its result is the same each time for a given student. While some cases of redundancy could be eliminated with a more complex syntax, most are caused by the generality required by the design of the language as successive application of modularized operators and the conscious decision to disallow use of explicit variables in the language. The system is also slowed by the fact that the language is interpreted dynamically, rather than being compiled. Nevertheless, the delay encountered for an application of this scale is scarcely noticeablelargely because the data involved is cached in RAM after its first access from disk, so redundant computations require no disk accesses. (ii) Developing an application of this level of complexity requires considerable system designing expertise. One needs to know how to represent the knowledge in hypermedia and how to build up a sequence of modular definitions. The way to structure a program in the Hermes language is to define a hierarchy of terms with descriptive names. In complex cases like the academic advising application, one must explicitly design a manageable hierarchy and choose meaningful names that will result in readable expressions. This is probably inevitable in any system. Once well designed, however, the system can be significantly easier to understand, modify, and extend than alternative implementations would be. While the result of the advice term looks like the output from a traditional expert system, the hypermedia flexibility is still there to explore the underlying knowledge base by navigation. Alternatively, one can reformulate the major query or execute a series of simpler queries using components of the advice predicate. Furthermore, the availability of all the information in hypertext makes it possible for users to browse the database. For instance, information could be linked to each course describing its content, hours, instructor, etc. The advantages of this approach in terms of flexibility probably outweigh the problems in settings like academic advising. The domain of academic advising is subject to frequent changes in rules and to many occurrences of special cases in student situations. Characteristics like these make the ability of end-users to revise and explore information important considerations. Predicates. In Hermes, the language can be integrated into the hypertext node and link structure in a number of ways. The first approach tried relied heavily on the idea of smart nodes, in which the inferencing power of the language is embedded in the nodes of the hypermedia. This was conceived primarily in terms of virtual structures, an extension of the fixed structures of textual or graphical nodes in traditional hypermedia systems, suggested by Frank Halasz (1988). The navigational (or hypertext) approach to query evaluation was used, as found in the Phidias query language, and the language was embedded in the hypermedia nodes. This was done to avoid simply gluing together two different paradigms (e.g., hypermedia and Prolog, or hypermedia and SQL, or HyperCard and HyperTalk) and to develop the querying or inferencing capability out of the hypermedia paradigm itself. The content of a smart node is not limited to the text or graphic originally entered into it. Instead the content is determined by the results of a query or conditional phrase associated with the node. The embedded query traverses the hypermedia network, so its result depends upon the current state of the network: the existence of other nodes, their links and their current content. When smart nodes are displayed, the appearance of the hyperdocument itself changes dynamically. Two forms of smart nodes were explored: conditional nodes and virtual structures. A conditional node contains a conditional phrase in the inference language and normal text or graphics. If the condition evaluates to true, the text is displayed. If the condition is false, nothing is displayed. For instance, in the academic advising application a node with the text, "Are you interested in a studio course?" might have the condition, if there are courses that have studio_types. Then the text would be displayed only if there actually were studio courses for the student to choose from. A virtual structure differs from a conditional node in that it contains only a query. Instead of fixed text, the system displays the result of the query. So, in the previous example, if there were studio courses and the user responded to the question with a "yes," then the yes response might be implemented as a link to a virtual structure node with the query, display all courses that have studio_types. The user would not see the statement of the query, just the results. Conditional nodes and virtual structures add significant flexibility to hypermedia. They allow specific nodes to be responsive to changing conditions in other nodes of the hyperdocument. For instance, decision trees can be implemented using smart nodes by basing new decisions on nodes that contain the results of previous decisions (see discussion of decision trees below). However, there is an important limitation to smart nodes. Suppose you had defined an inference computation for a specific node, embedded it in that node, and found that it worked fine. But now you wanted to apply the same computation to other nodes without explicitly entering the condition or query in each of the other nodes. More generally, suppose you wanted to apply the computation as an operation on an arbitrary list of nodes. This turns out to be a critical concern because it is important to be able to do this within the inferencing language itself. Smart linksor predicatessolved the limitation of smart nodes. Predicates are different from primitive links or defined link types. When a hypermedia system is designed, a set of link types is defined. For instance, in the academic advising application there are links of type proposed_courses from a student's node to his or her chosen course nodes, and other links of type prerequisites from course nodes to other course nodes. A smart link is a virtual link that is computed based on the definition of a term. For instance, a predicate might be defined as: required_prerequisites = proposed_courses that have prerequisites, with their prerequisites. Here, required_prerequisites would not be a primitive defined link type, but a computation or an inference. This is an example of a query using normal primitive links: display the proposed_courses for sandra. It would be evaluated by following the proposed_courses links from the student node sandra and displaying the nodes reached: *** PROPOSED_COURSES: 1. ENVD 2110 Architectural Studio . . . . This is an example of a query using smart links: display the required_prerequisites for sandra. It would be evaluated by substituting the definition for the computed link type into the query and displaying the result: ***PROPOSED_COURSES: 1. ENVD 2110 Architectural Studio *** PREREQUISITES: 1. ENVD 1000 Environmental Design Studio 2. ENVD 1014 Intro to Environmental Design . . . . The idea of substituting a definition for a term in a query is known as macro expansion. The definition of smart links as macros turns out to be an extremely powerful mechanism for the inferencing language. Because of the way the substitution is implemented, recursive definitions of smart links are possible (discussed below). This allows simply stated queries to evaluate tree structures and easily display transitive closures, in both breadth-first and depth-first orderan accomplishment not matched by relational query languages like SQL. The Hermes language distinguishes between macros and predicates. A predicate is like a macro; however, when its results are displayed, they are labeled to appear as though the predicate were a primitive link type. This is critical for the tacit understanding of the user. Now when the user says, display the required_prerequisites for sandra. the user does not need to know that required_prerequisites is anything but an ordinary link type. The result is displayed without any indication of the internal structure, like this: *** REQUIRED_PREREQUISITES: 1. ENVD 2110 Architecture Studio 2. ENVD 1000 Environmental Design Studio 3. ENVD 1014 Intro to Environmental Design . . . . In Hermes there are three kinds of links: * Primitive links, which are the traditional link types of hypermedia. * Macros, which add significant inferencing power by encapsulating computations across multiple links. * Predicates, which use the power of macros but hide the complexity from the user. Predicates like required_prerequisites had to be defined and the differences between types, macros, and predicates had to be explicitly considered during system development. However, the eventual end-user can take advantage of this computational power without knowing that no primitive links actually exist in the hypermedia between student nodes and their required prerequisites. The predicates look like simple links to the user and can be tacitly used as though they were simple primitive links. Smart links overcome the limitation of conditional nodes and virtual structures. Because macros and predicates are syntactically equivalent to primitive link types, they can be bound to arbitrary nodes or lists of nodes as if they were actual links coming out of those nodes. Smart links turned out to be so powerful and flexible that the academic advising application was developed almost exclusively with them. Decision trees. Another important programming techniqueparticularly for expert system applicationsis decision trees. A typical example of using a decision tree is categorization of fauna and flora. One proceeds through a sequence of questions posing alternative choices. Based on ones answers, the choices lead down a path through the tree of decisions to the answer, e.g., the name of the animal or plant corresponding to the choices. Here is an example from the domain of academic advising, implemented with virtual structure nodes (nodes containing queries to be evaluated).
Figure A-3. A decision tree as virtual nodes. The rectangles are virtual structures. Evaluating node Suggestion produces the message, Take ENVD_1000. Suppose we have the query, suggestion (this query consists simply of the name of a node). And suppose the node named "suggestion" contains the following DataList: if envd_semester of student is less than 3 then beginner, else advanced. Assuming that the proposition (envd_semester of student is less than 3) turns out true, beginner is evaluated. It contains the DataList, if there are envd_1000 that are contained in completed_courses of student then completed, else uncompleted. Suppose we take the branch of the tree to the simple uncompleted, which contains the text, "Take ENVD 1000." Then this text is displayed in response to the original query. The virtual structure nodes have implemented a decision tree in a way that is relatively easy to understand and to modify if necessary. The links through the hypermedia defined by the embedded queries reflect in a very straight-forward way the structure of the abstract tree of decisions. Here again, the system requires some analysis to set up, but once defined in the Hermes Language it is rather self-documenting. Variable binding issues. While the above implementation of a decision tree is appealing, it demonstrates the limitation of virtual structure nodes as well as their power. Note that in the last two queries the node student was referred to by name. If one next wants to evaluate the decision tree for another student, the new student information must be substituted in the hypermedia network that contains the virtual structures. The decision tree cannot be simply applied somehow to other existing nodes, let alone to arbitrary lists of nodes (the way predicates can). This is a form of the general binding problem, a consequence of avoiding the use of variables in order to keep the language easy to understand. In the Hermes Language one cannot say "If envd_semester of X is less than 3," except by defining a predicate to encapsulate that computation and applying the predicate to an arbitrary subject. That is why predicates are used so extensively in applications using the language. However, predicates have their own binding problem. Predicates are a form of Association. They must ultimately be applied to (operate on) a DataList in order to produce a DataList result. The input DataList is referred to as the binding subject. A predicate is like a function, f(x); eventually, its parameter, x, must be bound to a variable value in order to be evaluated. When it is used in the evaluation of a query, a predicate is implicitly (automatically) bound to whatever subject it is applied to. Therefore, any unbound relationship in the predicate definition is implicitly bound to that subject as well. However, predicates can have whole queries embedded in them and so a question arises concerning the subjects of these embedded queries. If there is an explicit subject node named in the embedded query, then there is no problem. However, predicates draw much of their power from binding to implicit subjects, as explained in the previous paragraph. Therefore, the Hermes language permits leaving the subject unnamed in an embedded query. In such a case, the implicit subject of the embedded query is bound to the last explicit subject of a query (i.e., to the subject of the query in which the embedded query is embedded, or if that query has no explicit subject then the subject to which its subject is bound). This procedure is based on the usual assumptions of the English language, so that language expressions behave the way English-speaking users would expect them to, without the user having to think in programming terms. For an example of the two binding mechanisms presented in the previous paragraph, consider the problem of determining what problems a student has with missing prerequisite courses. The query for this (prerequisite_problems of sandra) can be based on a predicate named "prerequisite_problems" (proposed_courses that have prerequisites_not_taken, with their prerequisites_not_taken) which contains a predicate named "prerequisites_not_taken" (prerequisites that do not include courses_taken). In this query, "prerequisite_problems" is bound to the explicit subject of the query, sandra. The other predicate used in its definition, prerequisites _not_taken, is applied to proposed_courses through composition. So prerequisites in its definition is bound to proposed_courses (i.e., we are concerned with the prerequisites of the proposed courses). The issue arises with courses_taken. These are not courses taken by the proposed courses, but by Sandra. According to the syntax of the query, courses_taken is part of an embedded query: courses_taken of X. The subject is left implicit, which to English speakers means it refers to the previous main subject, sandra. This is in fact the rule used for binding implicit subjects of embedded queries in the Hermes Language as well. The Hermes language solves the binding problem through the two mechanisms illustrated above. This allows predicates to exercise their power of leaving their subjects implicit, to be bound at runtime. The solution maintains the language's support of tacit understanding by corresponding to the intuitions of non-programmers. While it cannot handle arcane examples requiring binding to multiple or obscure subjects, it handles reasonable, humanly comprehensible examplesincluding arbitrarily deep embedding of queries. The example of prerequisite_problems is a realistic one, occurring in the academic advising application described above. The Hermes language also provides syntax options to specify bindings: the options that (last subject), this (expression), and those items are part of the languages syntax. These options provide an explicit choice of variable bindings, that can be left to their tacit defaults in many cases. These options fulfill some of the functions of variables using the familiar terminology of deictic reference in English. Recursive procedures. Recursive programming is a potentially powerful technique. It is particularly useful for processing trees of data, like family trees. In the academic advising application, tree structures appear in the list of course prerequisites. A full set of tree elements is called the transitive closure. A particularly interesting definition from the example domain of family relations is that of descendants: descendants: children with their descendants A programmer would recognize this to be a recursive definition. That is, it not only lists the descendants of the starting node, but the descendants of those descendants, the descendants of descendants of descendants, etc. until there are no more generations. A non-programmer might be able to see that this definition would produce such a result, without having studied recursive function theory in the abstract. Again, the non-programmer might not be able to generate recursive definitions easily from scratch, yet might understand them when seen. Note that the recursive halt condition is implicit: stop when there are no more of the specified links to traverse. This is a convention that is built into the Hermes language implementation. It relieves the end-user from worrying about the recursive out condition that causes so many errors in programming languages that require its explicit statement. The two primary approaches to enumerating a transitive closure by navigation through a tree structure are depth-first and breadth-first. Both of these approaches can be programmed in the Hermes Language. The following Predicate and DataList definitions produce a nested, depth-first listing of the transitive closure of course prerequisites: prerequisite_trees: prerequisites with their prerequisite_trees. ENVD_4550 and ENVD_4560 with their prerequisite_trees. The following Predicate and DataList definitions produce a flat, breadth-first listing of course prerequisites: prerequisite_lists: prerequisites and prerequisite_ lists of them. prerequisite_lists of ENVD_4550, without duplicates. The computation through trees has important applications in practical problems. For instance, in a hypermedia design rationale system of issues, subissues of the issues, subissues of the subissues, etc., it is useful to define the issue_trees, a depth-first listing of the whole tree of issues. If the issues can each have answers and arguments for the answers (as in the popular hypertext IBIS systems), then one wants to list deliberationsthe tree of arguments on the issue tree. This is straight-forward to do in the language. It is trickier to produce a list of the terminal issues, that is subissues at the leaves of the issue tree that have no subissues themselves. This can be done with a Predicate for terminal_issues: terminal_issues: if there are issues of issues then terminal_issues of issues, else issues. Defeasible reasoning. The Hermes language is also designed to take advantage of defeasible reasoning in an intuitive way. Defeasible reasoning allows a system to be designed with certain default behavior that results unless explicit action is taken to change it. Suppose in a hypertext network of issues and answers one wants to allow a user to accept, reject, or ignore answers by attaching status links to nodes containing words like "accept", "reject", "ignore", "don't care", or no links. One might also want to allow multiple status links from any given answer node. So there may be contradictory information attached to an answer, or no information at all. Suppose further that one wants to display an_important_issue unless all its answers have been explicitly rejected with status links to "reject". This would require defeasible reasoning, a very robust approach. The following query could be used: if there are not answers of an_important_issue that have no statuses that contain "reject" then an_important_issue, else rejection_message This query has to do with the resolution of answers to issues in the issue-base. This is a critical task for use of a Phi issue-base, yet it has not been supported in design environments like Janus and Phidias in the past. If issues are explicitly resolved by, for instance attaching status links, then related functions within a design environment like the display of palette items can respond to these decisions with expressions like the preceding query. Note that defeasible reasoning allows one to ignore all the possible combinations of potentially redundant or contradictory conditions (e.g., multiple status links from a given node) and express just the desired condition. This is supported by the Quantifiers in the Hermes language, such as all, most, no, the only one, at least one, etc. The end-user can formulate an expression based on a tacit understanding; the explicit computations are left to the implementation of the language
Go to top of this page Return to Gerry Stahl's Home Page Send email to Gerry.Stahl@drexel.edu This page last modified on January 05, 2004 |