Conceptual Frameworks and Computational Support
for Organizational Memories and Organizational Learning
![]()
Attention:
Information Technology and Organizations (ITO) Program
National Science Foundation
Room P-60 - PPU
4201 Wilson Blvd.
Arlington, VA 22230
Submitted by:
Center for LifeLong Learning and Design (L3D)
Department of Computer Science
and Institute of Cognitive Science
University of Colorado at Boulder
Dr. Gerhard Fischer, phone: (303) 492-1502, email: gerhard@cs.colorado.edu
http://www.cs.colorado.edu/~gerhard/Home.html
Dr. Jonathan Ostwald, phone: (303) 492-3547, email: ostwald@cs.colorado.edu
http://www.cs.colorado.edu/~ostwald/Home.html
Dr. Gerry Stahl, phone: (303) 492-3912, email: gerry@cs.colorado.edu
http://GerryStahl.net/Home.html
Planned Period of Support: September 1, 1997 - August 31, 2000
Amount of Support Requested: $969,524
![]()
"Conceptual Frameworks and Computational Support for
Organizational Memories and Organizational Learning"
This project will investigate computer support for learning, working, and collaborating in information-intensive organizations. It will focus on communities of practice (such as local area network managers, research teams) as subgroups within and across organizations. We will work with specific communities to design, test, and reflect upon organizational memories to support organizational learning.
Organizational learning is a process by which knowledge that is created or made explicit during work on tasks is captured, structured, maintained, and evolved so it can be accessed and delivered when needed to inform future tasks. Organizational memories can facilitate organizational learning by supporting communication within communities of practice, delivering information relevant to their tasks, letting them "grow" their own information spaces, and allowing them to collaborate using the World Wide Web (WWW).
The project will work with specific communities of practice to study their actual and potential learning processes. Based on the interpretation and assessment of these observations, and theories from the research literature or from our own previous work, we will develop and articulate a new conceptual framework for computational support of organizational learning. To assess and develop this framework, organizational memories will be prototyped in collaboration with the communities and assessed in naturalistic settings.
The organizational memory software (building on emerging WWW technologies and prior research on domain-oriented design environments) will extend our currently existing prototypes with innovative mechanisms for capturing, structuring, as well as delivering information. It will incorporate computational support to reduce the burden on users as well as end-user controls to empower users to adapt the memory to rapidly evolving needs. It will integrate the various software mechanisms into a coherent architecture and a system of meaningful user interactions for supporting effective organizational learning.
Research Issues. We will focus our research on: (1) how to capture knowledge and integrate the contexts of work; (2) how to sustain the timeliness and utility of evolving information; and (3) how to deliver relevant information actively and adaptively.
Approach. We will develop a conceptual framework for integrating working and learning in communities of practice. We will create organizational memories that include mechanisms to capture and represent task specifications, work artifacts, and group communications; facilities for practitioners to reorganize and sustain the usefulness of the memory; and techniques for access and delivery of knowledge relevant to current tasks. We will extend emerging WWW technology with structured web site interactivity, version control of evolving information, software critiquing agents, and end-user programmability.
Assessment. We will ground our designs and technical innovations in an assessment of the informational needs and organizational barriers to learning within communities of practice. We will focus our research by working specifically with communities of practice such as local-area network (LAN) designers and managers, the group of researchers working in our center, students in classes, neighborhood communities, and industrial work groups.
Expected Results. The proposed research will create (1) at the conceptual level: a unifying framework for organizational memory and organizational learning; (2) at the computational level: a generic architecture for organizational memories based on our prior domain-oriented design environments and prototypes for specific domains; (3) at the assessment level: a body of empirical results based on evaluations of the systems and the underlying theory in concrete organizational contexts.
![]()
![]()
Section 1. Results from Prior NSF Support
In our previous grants we have explored collaboration theory and technology in the design and use of high functionality software systems to support the work of individuals and small design teams. We have developed conceptual frameworks concerning (1) multifaceted architectures for domain-oriented design environments and computational support for lifelong learning integrated with work processes ; (2) the maintenance and evolution of growing information bases through seeding-evolution-reseeding ; (3) embedding communication in and routing work through design environments ; and (4) providing knowledge delivery with critiquing and other agent mechanisms .
Our research in domain-oriented design environments explored the shortcomings and limitations of generic systems and integrated different aspects of design support environments . Aspects investigated included active help delivery systems ; critics ; information filtering ; adaptive and adaptable systems ; end-user modifiability ; and incremental formalization of large information spaces .
The major new aspect of this proposal is to move from a primarily individual perspective (e.g., individual lifelong learning) to an organizational perspective. In our proposed project, we will develop and study a form of organizational memory based on our model of domain-oriented design environments.
In order to gain a deeper and broader understanding of the research issues associated with this shift, we organized a research symposium in May 1996 entitled "Computational Support for Continually Evolving Organizational Knowledge Bases," which brought together a dozen of the leading researchers in organizational memory and organizational learning (for details, see: http://www.cs.colorado.edu/~ostwald/symposium/symposium.html) and we participated in a workshop at the CSCW’96 conference entitled "CSCW and Organizational Learning."
The proposed project builds on ideas and technologies from prior work. It expands them by focusing on organizational issues and by exploiting and redirecting the emerging WWW support mechanisms for organizational learning and organizational memories. The move to the WWW is a response to the limitations of our past closed systems, and the emphasis on practitioners sustaining information evolution is a response to the short lifetimes of our domain-oriented knowledge bases. In other, related prior NSF research (see list at the beginning of this section) we have established ongoing collaborations of our research center with community organizations, industrial partners, and interdisciplinary academic departments in Boulder as well as world-wide; the proposed project will deploy and assess our research within these organizations.
![]()
Section 2. Conceptual Framework
Our approach to organizational memories and organizational learning focuses on communities of practice as the unit of analysis, for reasons discussed in this section. We will analyze interdisciplinary sources to provide a basis our theoretical framework, including educational theory (constructivist learning, e.g.,); design methodology (design rationale); cognitive psychology (distributed cognition); social theory (activity theory); anthropology (situated action); philosophy (epistemology); sociology (communities of practice); management science (organizational learning); and computer science (intelligence augmentation).
The concepts introduced in this section will be used to guide our proposed project and to assess its accomplishments. This framework suggests issues to explore, needs to support, approaches to try, and questions to evaluate. Within this context, we will design and prototype software systems to support work, learning, and collaborating in specific domains. To ground our research in the domains, we will work closely with practitioners from relevant disciplines, observing their work patterns, joining in participatory design with them, and having them try out our prototypes.
Communities of Practice
A community of practice is a group of people who share a set of activities and who interact to achieve shared objectives and to maintain their community . Unlike an organization, which has well-defined bureaucratic structures, a community of practice is often an informal network of people who share expertise, war stories, and practical advice . Such communities typically form through personal ties in order to help each other keep up with new organizational or technological developments that impact their ability to get work done. These groups have a life of their own that helps them accept newcomers and survive when old-timers leave. Because of their unofficial status, communities of practice often go unrecognized and unsupported. As the role of these communities grows ¾ particularly in information-intensive settings ¾ it becomes increasingly important to understand them and to provide computer tools to support their functioning.
We have begun to work with local-area computer network (LAN) designers and managers at the University of Colorado in order to understand their needs for computer-supported organizational memory. This community exists within a larger organizational structure and cuts across official boundaries based on practical needs to interact and to share information. Their information needs include technical knowledge of their work domain (e.g., what are the latest routers on the market and what are their costs, capabilities, problems, etc.), local lore (the manager of LAN x is a UNIX guru), and specific arrangements (the print server in LAN x is configured as y for reason z). The fact that most of this information is kept in the minds of individuals makes it difficult for other community members ¾ particularly newcomers who do not yet know who has what information and have not established personal relations ¾ to do their jobs.
We understand practice as situated activity in which practitioners pursue activity within concrete physical, technical, cultural, and interpersonal circumstances . Rather than modeling practice as the execution of explicit goal-oriented procedures, we are interested in the established, generally unstated practices of a community that determine how things are done by its members ¾ what Bourdieu calls the habitus or the tacit culture of the community .
The daily practice of a community not only produces the community’s work products, it also reproduces ¾ more or less effectively ¾ the preconditions for the future of the community. New members learn community practices as they engage in them actively, not necessarily through didactic instruction . As the community practice produces learning, it reproduces its own future. Because much of what needs to be passed on is never articulated explicitly, education takes place through apprenticeship relationships and training of reflective practitioners . This learning can be facilitated by a group memory that includes evolving artifacts of communal practice .
The theory of practice addresses a number of problems that have arisen in the human-computer interaction community , and that have implications for organizational memory and organizational learning. It broadens the analytic scope to take into account the social context in which people use computers . The social context of a community of practice provides motivation to pass knowledge from old-timers to newcomers as everyone tries to increase their participation and reproduce the community . It ties working and learning together into a single framework. The introduction of new computational memories into this process will transform the social fabric, the cycles of learning, the interpersonal needs of the group . The design of organizational memories must take such implications into account.
Finally, the theory of practice provides a perspective on work in which sustainability means not maintaining the status quo, but rather maintaining a constant flux of new members and new knowledge. Computational environments for communities of practice must support this sustainability by allowing members to extend, update, and restructure organizational memory continuously. They must also make it easy to redefine who has access to what information in response to continual shifts in roles, assignments, and understandings. Sustainability of organizational memory means keeping it tuned to the changing needs of individuals because organizational learning takes place in parallel with the lifelong learning of community members .
Our vision of organizational learning focuses on recording knowledge gained through experience (in the short term), and actively making that knowledge available to others when it is relevant to their particular task (in the long term) . A central component of organizational learning is a repository for storing knowledge ¾ an organizational memory. However, the mere presence of an organizational memory system does not ensure that an organization will learn . Today, information is not a scarce commodity; the problem is not just to accumulate information, but to deliver the right knowledge at the right time to the right person in the right way. Organizational learning happens only when the contents of organizational memory are utilized effectively in the service of doing work .
Traditionally, people went to school or attended training seminars or studied books to learn facts that might be needed for later work. When working and learning are integrated in the process of organizational learning, information needed for a current task is available just-in-time .
For sustained organizational learning, three seemingly disparate goals must be served simultaneously. Organizational memory must:
| be extended and updated as it is used to support work practices; | |
| be continually reorganized to integrate new information and new concerns; and | |
| serve work by making stored information relevant to the new task at hand. |
We envision organizational learning as a continuous cycle in which organizational memory plays a pivotal role:
| Individual projects serve organizational memory by adding new knowledge that is produced in the course of doing work, such as artifacts, practices, rationale, and communication. | |
| Organizational memory is sustained in a useful condition through a combination of computational processes providing information (e.g., ) and people actively contributing . | |
| Organizational memory serves work by providing relevant knowledge when it is needed, such as solutions to similar problems, design principles, or advice. |
The intimate relation between organizational memory and work practice implies that the contents of organizational memory must be easily accessible within the context of work. Computational support for organizational learning, therefore, must tightly integrate tools for doing work with tools for accessing the contents of organizational memory.
Through everyday work, a community of practice generates knowledge that may be critical in its future . The community's practices are generally tacit, not written down or expressed in words . Often, the only time that the knowledge exists in explicit form is when it is being actively reflected upon and used to do work . By capturing this knowledge as it arises and storing it in repositories of organizational memory, a community can preserve information that is otherwise lost. Rather than building organizational memories by interviewing experts to formulate rules for expert systems, we will study the practices by which organizations do their work and communicate knowledge, and to capture the knowledge as it is articulated during work. We want to create "living" organizational memories ¾ information spaces that are sustained and managed by the people who use them in their work, rather than by people in other parts of the organization who may have requisite technical expertise but are not intimately involved in the actual work practices .
A principal challenge for organizational learning is to capture a significant portion of the knowledge generated by work done within a community. Experience with organizational memories and collaborative work has exposed two barriers to capturing information:
| Individuals must perceive a large enough direct benefit in contributing to organizational memory to outweigh the effort . | |
| The effort required to contribute to organizational memory must be minimal so it will not interfere with getting the real work done . |
The consequence of these barriers means that processes of information capture, structuring, and delivery must be computationally supported as much as possible or they will simply not get done.
Organizational memories are information systems that are used to record knowledge for the purpose of making this knowledge useful to individuals and projects throughout the community of practice and into the future . Ideally, an organizational memory allows individuals within the community to benefit from the experiences and insights of others, by actively informing work practices at the point when the information is actually needed . That is, an organizational memory should not be simply a passive repository of information, but an interactive medium within which collaborative work can actually be conducted and through which communication about the work can take place and be situated.
It is often assumed that the Internet solves the problem of organizational memory. While the World Wide Web (WWW, web) on the Internet functions primarily as a broadcast medium and therefore lacks the interactivity needed, intranet structures can indeed be designed to implement organizational memories. An intranet is a small version of the web, in which access is restricted to a particular community. It uses the same technology standards (e.g., TCP/IP, HTTP) as the global web. Generally, intranet information is stored in a database rather than in fixed HTML documents, so it can be displayed dynamically to use the latest information and to respond to unique queries. Intranets are rapidly replacing traditional client/server systems as the preferred technology for computer-based organizational memories. Intranets make more flexible organizational memories because users can access them with a web browser on any computer and because the computation of the client display logic, the organization's business rules, and the database query logic can execute on different computers.
All the major software companies are rushing to support the building of intranets. Microsoft's Office 97 applications, for instance, can publish web documents directly. Database environments are beginning to support live data editing through forms on the web (using ODBC and JDBC database connection standards). Special environments such as Tango allow a developer to design web data entry forms quickly using visual drag-and-drop tools. Finally, an extraordinary wave of sophisticated development environments incorporating scripting languages are appearing (at least in beta or vapor ware): Borland's IntraBuilder, IBM/Lotus's Notes/Domino, Netscape's LiveWire, Microsoft's FrontPage, Oracle's InterOffice, Novell's GroupWise, PowerBuilder, Cold Fusion, SuperNova, etc.
Intranet technology seems to offer a promising approach and substrate for building organizational memories. However, these environments do not by themselves suggest how to integrate work and learning, how to capture new information, how to support information evolution, how to deliver relevant knowledge, or how to computationally support these processes under user control. Yet, that is precisely what is needed. We maintain that systems to support organizational learning should take an analogous approach to our domain-oriented design environment support for informing collaborative design work. We propose to explore organizational memory that does this, using commercially available intranet technology as an enabling technology .
![]()
Section 3. A Scenario of Organizational Learning Using Organizational Memory
To address the issues reviewed in the previous section, we propose to prototype an organizational memory system named WebNet that explores these issues within concrete work contexts. One community of practice with whom we plan to collaborate in designing and assessing WebNet is local-area network (LAN) designers and managers at the University of Colorado. Following is a vision of how WebNet might be used by this community. The scenario illustrates how WebNet integrates working, learning, and collaborating. The purpose of the scenario is to present concrete examples of the kinds of information and mechanisms that WebNet will include, as a background to the discussion of computational support in the following section.
Kay is a geography graduate student who works part-time for network services. Kay logs into WebNet through her web browser, and WebNet responds by displaying Kay's WebNet home page. Kay had designed this page to include information sources she needs to check regularly; it delivers information that is related to her LAN and to her job responsibilities. Kay's WebNet home page contains a message list (with email and comments directed to Kay from co-workers and clients), a to-do list for tracking her current projects, and a community-wide task list of jobs that need to be done.
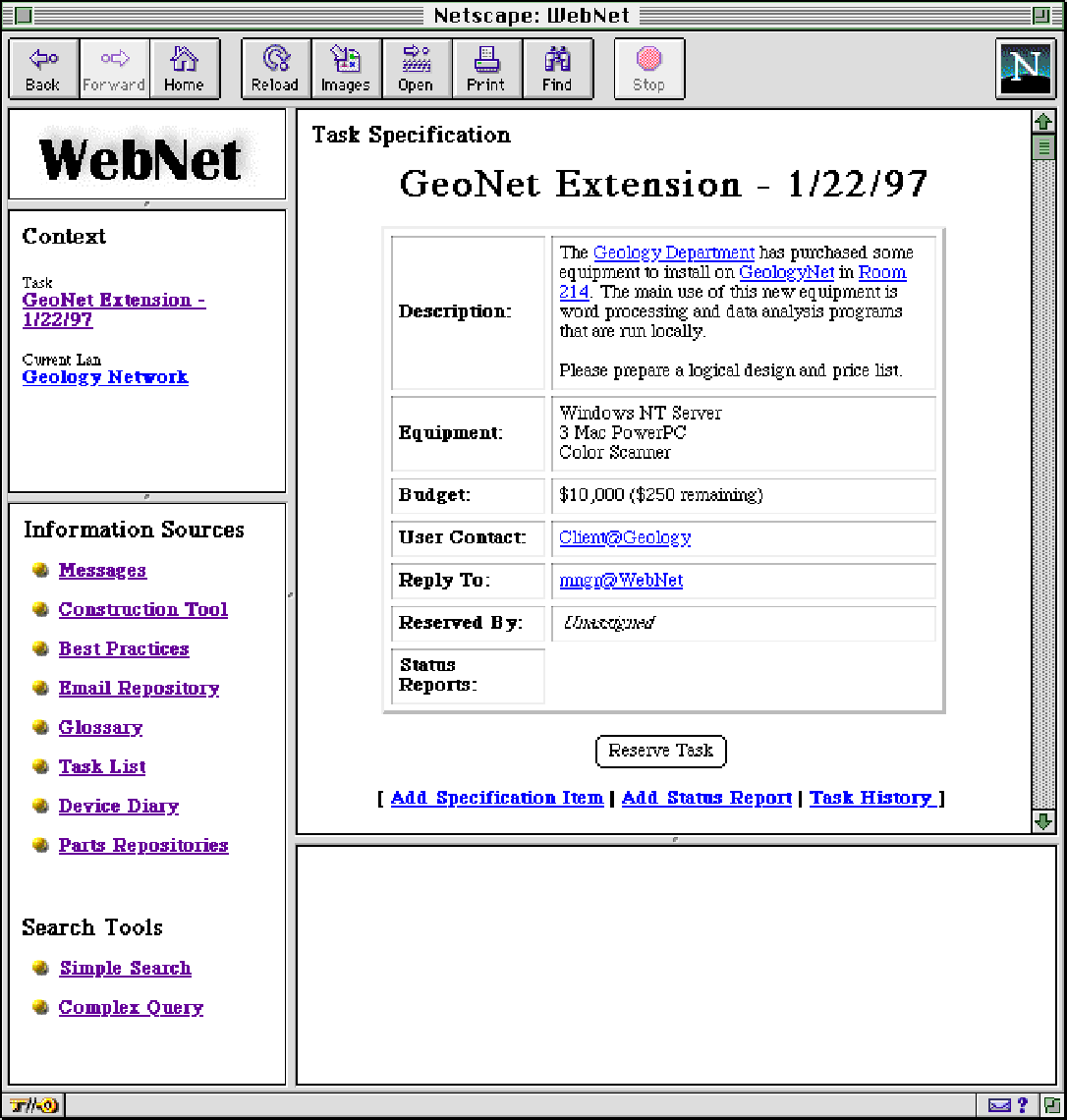
Integration of the Work Situation. Kay notices that she has a message from Ray, her supervisor, suggesting a new task for her. Kay selects the Geology job from the task-list and WebNet displays a task specification page (see Figure 1-A). The task specification says that a new Windows NT Server and three Macintosh PowerPC workstations are to be connected to the Geology Network in room 214. Kay's task is to prepare a logical design, parts list, and price breakout for the new installation. The task specification also provides a budget and contacts within the Geology Department. Kay clicks on "reserve task" to inform her co-workers and WebNet that she will take care of the task.
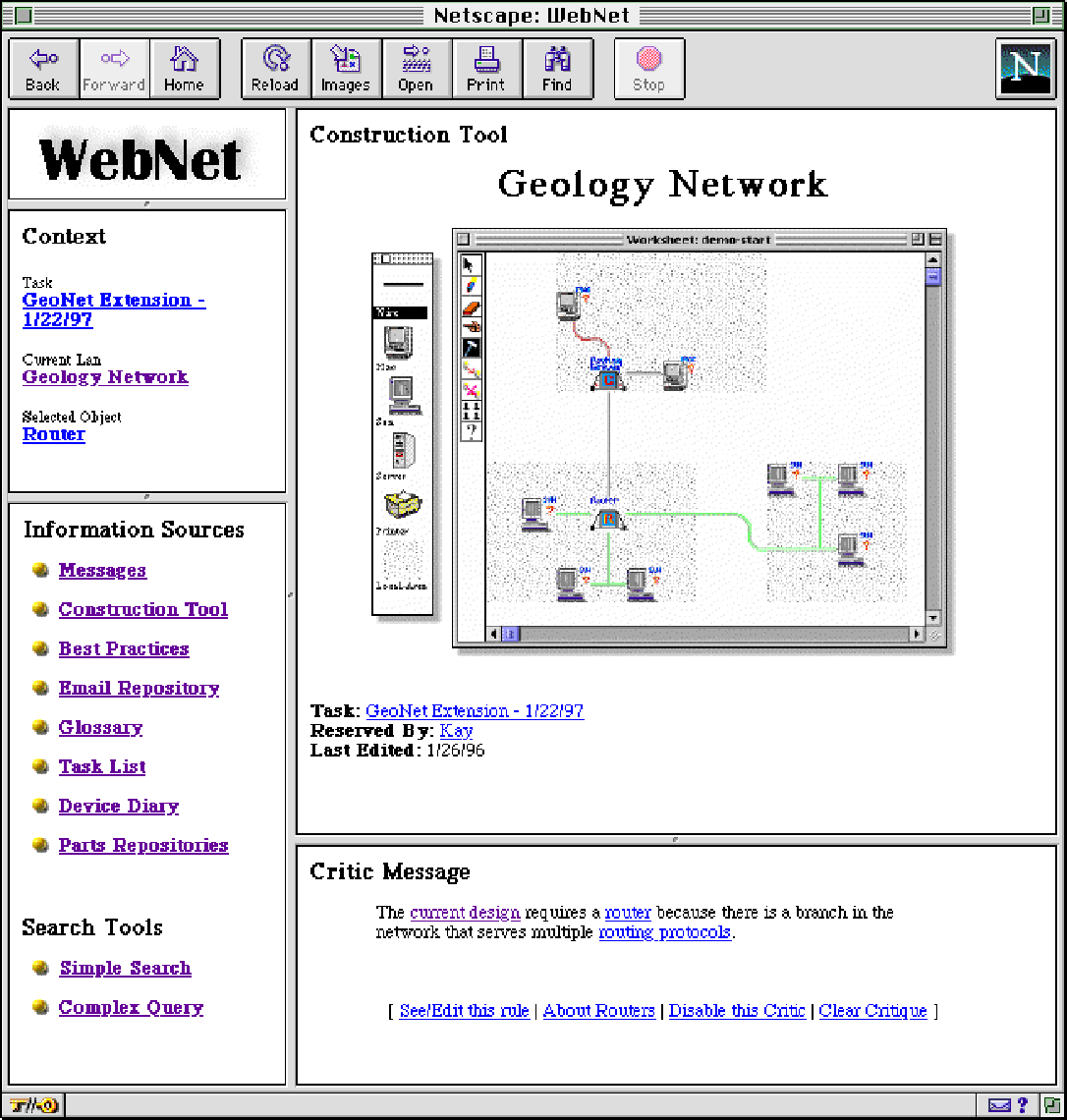
When Kay clicks on "Geology Net" in the task specification, WebNet displays a logical map of the current Geology LAN in the knowledge-based construction tool for LANs. The construction tool provides a work area, a tool bar, and a palette of network design elements that can be selected with the mouse and placed in the work area (see Figure 1-B).
Kay begins to plan the installation of new equipment by adding the purchased equipment to the existing logical network using the construction tool. She selects the Macintosh icon from the palette and places three workstations into room 214. Then she selects a Windows NT icon and places it. Finally, Kay connects the new equipment by dragging the cable to reach from the existing network to each of the new machines.
Information Delivery. When Kay has connected the machines to the network, WebNet beeps and places a blinking router icon at the junction between the existing network and the portion that Kay has added. A critic message appears in WebNet’s lower pane, indicating that the configuration she has specified requires a router. Kay knows what a router basically does and why a router is needed in this configuration. However, she doesn't know what specific router is needed or how much the needed router should cost.
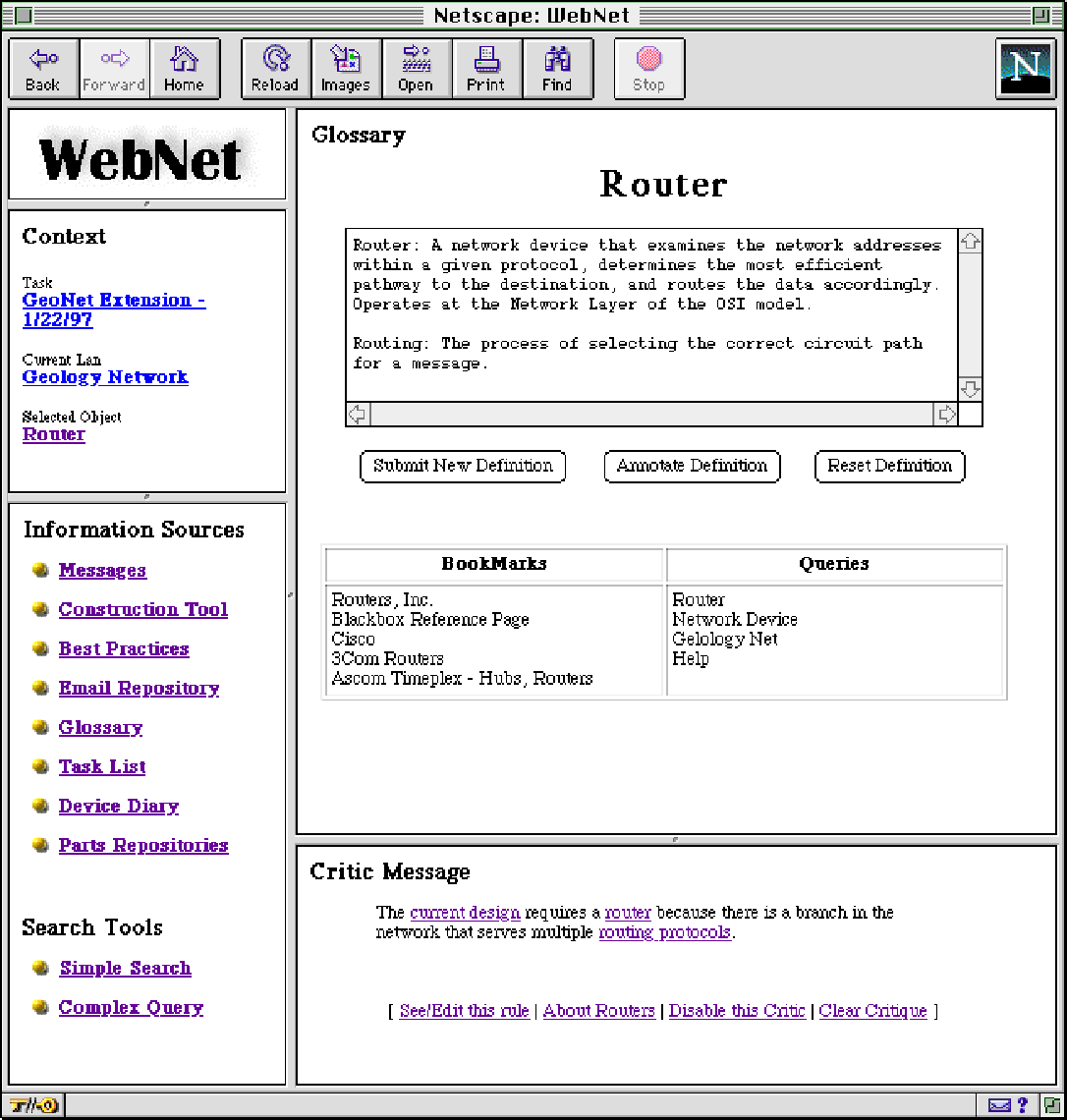
Kay selects the link to "router" in the critic message, and WebNet brings up a new page containing information about routers (see Figure 1-C). The router information page contains a short description of routers from the WebNet glossary, a collection of definitions for common networking terms.
Kay finds that this definition is also too general so she decides to check out some displayed bookmarks. Bookmarks consists of a catalog of URLs that previous WebNet users had found helpful and had added. WebNet has displayed the bookmarks that are relevant to the current design. To Kay's disappointment, the bookmarks point to router manufacturers' pages, which contain detailed specifications about the routers, but not the type of information that Kay needs.
Kay decides to search WebNet's information space. WebNet supplies a default query based on the current LAN design context: "list all information about routers". Kay can use this default to search WebNet, or she can modify the default query by simply typing in more words to the query box. More sophisticated searches may be performed by selecting the "more choices" button, which brings up a query window containing an interface for constructing queries involving particular information sources within WebNet, author, dates, and specific networks, in addition to the search string.
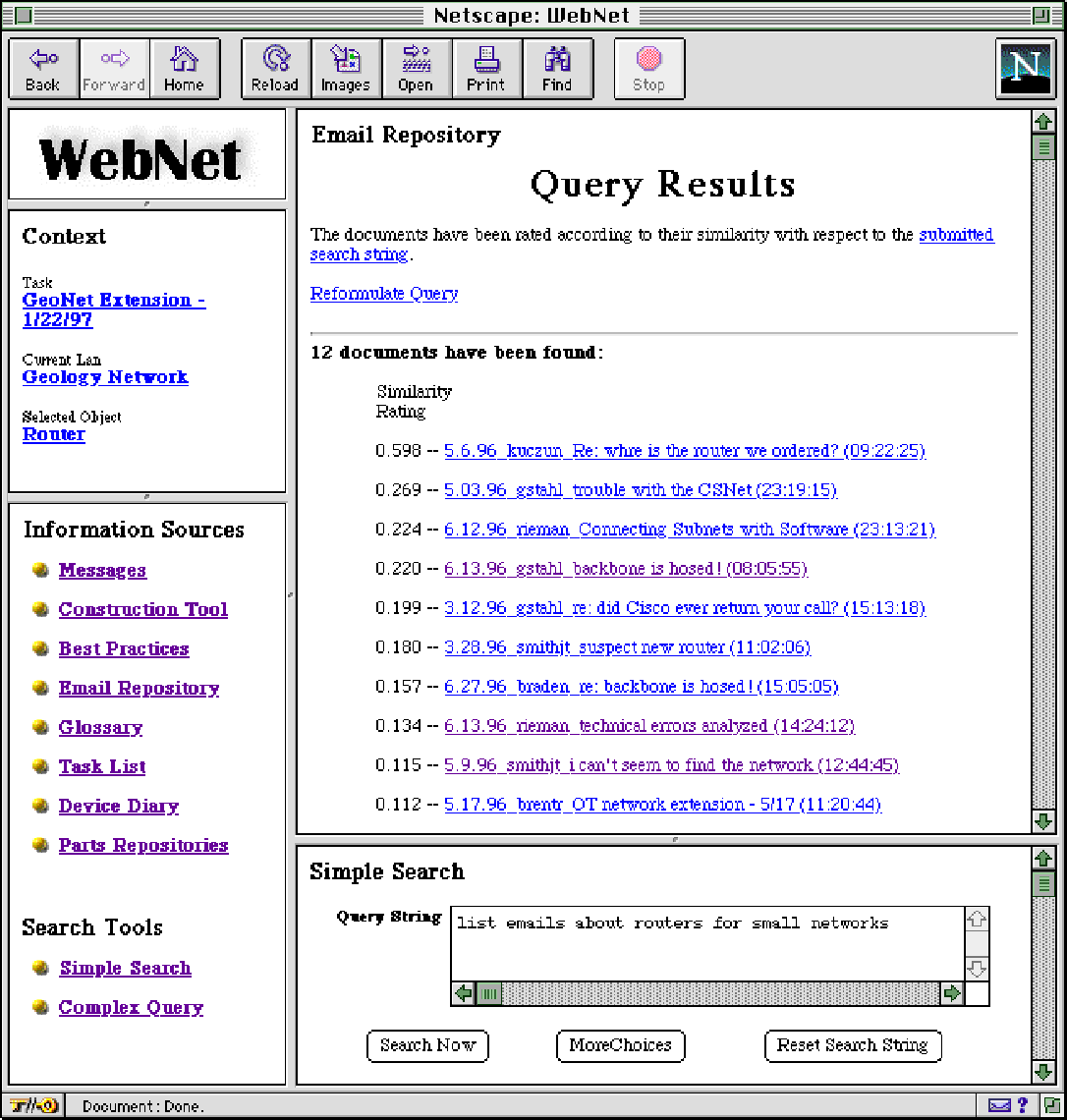
Kay begins her search by selecting the "Search Now" button. WebNet displays links to many pieces of information, ordered by their relevance to the query string. Overwhelmed by the amount of information, Kay decides to refine the query. She selects "more choices" and restricts her search to email written in the past six months and modifies the query to "list emails about routers for small networks" (see Figure 1-D).
A.
B.
C.
D.
| Figure 1. WebNet Scenario Pages. A. Task Specification. B. Construction Tool loaded with the Geology Network. C. Information about Routers. D. Query Results in GIMMe. |
This query returns just twelve email messages. One describes how Pat used a PC as a router in a small LAN. Pat's email indicates that routing in software can be cheaper and more flexible than through a hardware router, although there is a performance penalty.
Sustaining the Organizational Memory. Kay decides that Pat’s solution may also work for the Geology Network. She adds information about her solution to WebNet’s glossary, making it available to other members of the network design community. She includes a link to Pat's email message, and also a link to her design, to connect these related pieces of information. Now other designers in Kay’s community will benefit from the knowledge Kay uncovered through her work.
Kay returns to the task description page and adds a status report describing her proposed design. She tags the status report to be sent to Ray, to the Geology contact person, and to Pat, asking for feedback on her decision.
![]()
Section 4. Computational Support
The conceptual framework presented in Section 2 implies that organizational memory systems supporting organizational learning must be tightly integrated with tools for doing work in order to capture new knowledge, to allow the community to sustain it, and to actively deliver information when needed. Only if the organizational memory includes representations of the work context can it decide what information is relevant to the current task. This project will explore mechanisms for the software to make such determinations. The scenario showed a simple example of one person interacting with such an organizational memory.
This section presents our technical approach. Our approach extends prior work by us and by others; it also takes advantage of emerging intranet technologies. The significance of this project is to integrate the techniques in a theoretically motivated way and to assess how well they can address the practical issues confronting communities of practice in the information age. After reviewing our prior work and the work of others, this section will discuss some mechanisms for addressing our core research issues:
Relation of Our Prior Work to Proposal. We have created and assessed design environments for the following domains: kitchen design , programming , user interface design , voice dialog design , simulation design , lunar habitat design , service provisioning , and LAN design . In particular, we investigated how such systems could support the location , comprehension , modification , querying , filtering , and sharing of information in large information spaces of domain knowledge.
This prior work has contributed to a prototypical architecture for domain-oriented design environments, which integrates working and learning with components for: (a) construction of the design artifact, (b) a knowledge base of design rationale and artifact designs, and (c) computational critics that actively deliver relevant knowledge. The proposed project will generalize from this prototypical architecture to one having the following general functions: (a) representations of the work/collaboration context, (b) a rich, sustainable information space, and (c) mechanisms to map from the work context to relevant information for delivery.
Just as our work on design environments involved the interplay of multiple software components (e.g., construction, simulation, specification, gallery, catalog, rationale, critiquing, etc.) to deliver relevant design rationale, the proposed project will investigate mechanisms that deliver timely knowledge to practitioners by retrieving items from the information space that are related to the current work context. We will discuss our approach to implementing these mechanisms in the remainder of this section, after we relate our approach to that of others.
CSCW and Distributed Artificial Intelligence. Our approach distributes work and control between human practitioners and computational agents embedded in organizational memory. Our paradigm shares a large number of research issues with two related areas: (1) Computer Supported Cooperative Work (CSCW) , which emphasizes communication and collaboration among humans mediated by computer; and (2) Distributed Artificial Intelligence (DAI) , which emphasizes communication and collaboration among computational agents. In order to enrich CSCW environments with computational agents, the information content must be at least semi-formal. By studying systems with no humans directly involved, DAI focuses on related but primarily different research issues, and it is not faced with some of the challenges unique to human-centered agent-based systems.
Semi-formal Systems. Our approach to formalizing information in the organizational memory attempts to avoid the need for complete formalization without placing an unmanageable burden on the people who use the system. By representing the contexts of work, we establish a shared understanding of that context by the system and its users. By combining automatic capture of information, incremental formalization of stored knowledge, and end-user control over structure, we try to facilitate a workable balance. Related work on semiformal systems indicates that formalization need not be complete to be useful in aiding communication and collaboration .
1. How to capture knowledge and integrate the contexts of work
We will combine several mechanisms for embedding work and communication in a computational information system that we implemented and assessed in our previous NSF grants. In Janus and similar design environments, the construction of a design artifact takes place in a construction component that uses a palette of domain items so that the software can track the semantics of the design. In the Remote Exploratorium , the domain items in this palette can be exchanged within a virtual community through a web page within the system. In the Indy system for LAN design , post-it notes and other annotations can also be embedded in the construction area. The Kid system incorporated a specification component to capture and represent design goals. EVA routed design ideas through a shared computational repository. In GIMMe email is sent through and archived in a group memory. These mechanisms can all be used in organizational memories. The scenario illustrated several. Kay worked on designing the extended LAN within a construction/simulation component and she found critical information in an email component based on GIMMe.
Our organizational memory systems will generalize the notion of representing the contexts of design. In addition to representing the layout of an artifact or its specification criteria, a system can, for instance, represent the people involved ¾ either as individuals or as workers in certain organizational roles. The Hermes design environment explored a perspectives mechanism that tagged versions of information as belonging to different perspectives: different system users chose to retrieve information according to their profession (e.g., plumbing or electrical); domain (residential, commercial, industrial habitats); or organizational role (designer, supervisor, manager). Situating knowledge delivery within Janus, Kid, or Hermes-type contexts ¾ constructions, specifications, perspectives ¾ can facilitate the selection of relevant information.
In the context of LAN design and management, WebNet representations of the problem context will include: physical layout of equipment; logical layout of functional components; simulation of major network traffic sources and routers; performance specifications; professional perspectives; organizational business rules; problem reports; and email discussions. Each context representation will require its own user interface to allow people to modify the characteristics and effects of the representation as well as to instantiate representations of specific tasks. Each representation will affect the selectivity of the system’s knowledge delivery.
We will use mechanisms for communication capture such as those we used in the GIMMe email archive. GIMMe works this way: a community establishes an email alias for all communication of general interest to the group. In addition to members getting the email, it is also sent to a group memory archive. Here it is indexed for full-text search (using latent semantic indexing, described below) and made available for searching and browsing by community members. Members can also reorganize the mail by categories. Not only can members stop reading their daily group email and periodically scan GIMMe by categories of interest, but new members can learn the group's history, and all members can retrieve prior discussions and decisions. GIMMe's functionality will be incorporated in WebNet, where it will be enhanced with tools to sustain its evolution and to actively deliver relevant contents based on work contexts.
2. How to sustain the timeliness and utility of evolving information
The approach to sustaining information is based on an extension of our model of system evolution (ìSERî). We want to empower practitioners to evolve their own information spaces in a sustainable way. This requires making the web interactive (with DynaSites) so information can be changed as it is used. It also requires structuring mechanisms (such as perspectives) for organizing changing information.
Sustainable Evolution. In evaluating our domain-oriented design environments, we observed that the information stored in the knowledge bases soon became obsolete, as did the system functionality itself. Our seeding, evolutionary growth, and reseeding (SER) model is an attempt to see how community members can evolve their information systems . The model distinguishes three categories of professionals involved in creating, maintaining, and using an organizational memory:
| Substrate producers. These are the people who create the underlying technology. For our project, these are the producers of intranet development environments and other substrates. | |
| Memory designers. These are the people who design and implement an organizational memory. For our project, these are members of our research group. | |
| Practitioners. These are the people who use the organizational memory in their work practices. For our project, these are the communities of practice that collaborate with us and try out our prototypes. |
The SER model consists of the following three processes:
| Seeding. In the seeding process, memory designers and practitioners work together to instantiate an organizational memory seeded with domain knowledge and local information. | |
| Evolutionary Growth. In the evolutionary growth process practitioners add information to the seed as they use it to do work. Work artifacts and communications accumulate in the organizational memory, resulting in growth of memory contents. In addition, new work produces needs for new system functionality and structures. | |
| Reseeding. In the reseeding process, memory designers and practitioners reorganize and reformulate information so it can be reused to support continuing tasks. |
In the proposed project we want to investigate the possibility of going beyond our prior reseeding model by providing mechanisms for communities of practice to sustain the growth of their organizational memories without a distinct reseeding phase. Organizational memories should be able to evolve in symbiosis with their communities of practice like biological species evolve with their environments ¾ with no interventions needed from outsiders. Incremental formalization techniques can be used to automatically add computationally interpretable attributes to information that has accumulated during the evolutionary growth. Formalization of information increases the system’s ability to structure and retrieve the information, and thereby generalizes the information content beyond the specific context in which it was originally added. Empirical evidence shows that, within communities of computer users, technically proficient "local developers" emerge who are willing and able to perform many system modifications . WebNet will include mechanisms for communities ¾ especially their power-users ¾ to use to sustain the usefulness of the organizational memory continuously, thus reducing the need for a separate, disruptive reseeding phase that requires the memory designers to return. We have begun to explore this possibility with GIMMe, which allows members to reorganize as well as search and browse its email repository. We will make use of open industry standards so we can take advantage of future technological advances to increase substrate functionality, too, with minimal disruption.
Interactive Web Sites. Technologies for intranets are proliferating. However, these commercial products are very generic enabling technologies. They provide tools for building organizational memories but do not by themselves solve the complex issues of capturing, structuring, and delivering information.
Perspectives. In prior work we have explored a "perspectives" mechanism that will be adapted to DynaSites. Perspectives are important for sustaining evolution in collaborative information spaces . They allow different changes to the information to be maintained simultaneously in different perspectives. This way, people can make successive changes to the content or organization of information without negating the effects of previous changes. For instance, if one design group has completed an artifact that satisfies all relevant critic rules and saves the artifact in their group perspective, then later changes to the critic rules by another group will not affect the subsequent evaluation of the artifact within its original perspective. In such cases, perspectives provide a versioning system for organizing and sustaining a memory system that evolves over time.
3. How to deliver relevant information actively and adaptively
The standard mechanisms for retrieving information from the Internet or from intranets yield frustrating results . Indexers and search engines such as Yahoo and Alta Vista work best when information is structured ¾ but the web is not. Typical first searches return hundreds of thousands of hits, with follow up queries returning either still unmanageable thousands or none at all. Attempts to "pull" down information of interest automatically using software agents (bots) is not yet practical ¾ there are still too many unresolved issues involving how to specify relevance through end-user programming or otherwise. While there is much current work on software agents as a means to aid users in locating information in large information spaces (e.g., ), most of this work either relies on the user to explicitly formulate a query or relies on an implicit user model. "Solicited push" [Wired, 1997] through subscription to specialized or reliable information services is likely to be a popular solution for receiving domain news, but it does not meet the needs of just-in-time learning. Once more, none of the generic solutions integrate information delivery with work.
In our prior work, we have addressed the retrieval problem with query by reformulation , filtering , and critics . In organizational memories, we want to empower practitioners to take maximum advantage of shared knowledge. However, we do not want users to have to formulate database queries as such ¾ that requires professional training and knowledge of data storage structures. We are interested in providing as much software support as possible in formulating initial queries, letting users select from catalogs of queries, and helping people to reformulate queries at a level of abstraction corresponding to how they think about their work tasks. This means integrating the information delivery process with the work context with mechanisms like critics. Another mechanism for doing this is suggested by latent semantic indexing (LSI). Finally, we propose to develop an end-user scripting language for practitioners to reformulate queries.
Critics. Our domain-oriented design environments used the context of constructed artifacts, specified design goals , and selected perspectives to guide retrieval. Computational critics in these systems are agents that monitor the changing work context and identify potential information needs; when such a situation is identified the critic offers to deliver relevant information. Specifications can be used to select different sets of critics, and perspectives can reinterpret the behavior of the critics . Critics remain an important mechanism for organizational memories, but we want to find additional mechanisms to map from representations of the work context to relevant information.
LSI. To combat the brittleness of keywords in searches, we use latent semantic indexing (LSI) . We have experience using this with GIMMe, where it provides the primary access to archived email. LSI works by building a multidimensional scaling space through a statistical analysis of all the vocabulary in a textual corpus such as an organizational memory. Using this, LSI can locate items that are closely related to a given word or a longer phrase; it is not restricted to items that contain the exact keyword. LSI nicely augments the use of an embedded work context to help locate relevant information. For example, a textual problem report or a specification document can be used directly as an LSI query to retrieve stored documents that are semantically related (i.e., that deal with the same problems or with related machines and people). In this way, a document in the work area, such as a task description or a problem report, can be used by LSI to find other documents (emails, procedure manuals, previous problem reports) that are related and could prove helpful.
Scripting Language. Because information-intensive work is creative and communities of practice are dynamic, the retrieval of needed information must be under the control of the users. An organizational memory should allow practitioners to modify the information retrieval processes themselves. We will include an end-user scripting language to allow non-programmers to formulate and modify queries. We developed similar scripting languages in our Hermes and Agentsheets design environments. The syntax and vocabulary of the language will reflect the structures of the DynaSites database schema and representations of the work contexts, but a drag-and-drop interface to the language will shelter the user from worrying about these matters. In the scenario, for instance, Kay formulated the query, "list emails about routers for small networks."
![]()
Section 5. Assessment in Practice
Our project approach incorporates ongoing assessment of our conceptual framework and computational mechanisms. The framework suggests important requirements and mechanisms; our success in designing the mechanisms and the results of assessing them in use will reflect back upon the theory, highlighting important issues for organizational memories and the communities that use them.
We will assess our conceptual frameworks and prototypes in a variety of settings for organizational learning, such as those discussed below. In each of these settings, efforts to enact organizational learning will focus on reconceptualizing the use of technology for organizational learning, rather than simply "gift-wrapping" traditional frameworks with new technologies.
LAN Design Community. The domain of LAN design and management is appropriate because work is done by a community of practice; LANs are not designed once and for all but evolve over time; LAN design relies upon an enormous and rapidly changing information base; and LAN managers do much of their work on computers. Within this setting we will assess the integration of working and learning, new forms of collaboration enabled by our systems, and the ability of the community to sustain their computational environment over time.
Boulder County Healthy Communities Initiative. BCHCI is a community-based effort (of approximately 500 citizens coming from different backgrounds) to identify major trends and implement positive change on issues that affect the long-term health, quality of life, and sustainability of Boulder County. The concerns of BCHCI are (1) to engage citizens as self-directed learners who understand sustainability and can actively participate in design solutions, and (2) to turn BCHCI into a learning community that benefits from citizen input. Our relationship with BCHCI provides a unique opportunity to establish an organizational memory and study organizational learning within a community setting.
NYNEX University. We will build upon our ten-year relationship with NYNEX to reconceptualize organizational learning in industrial settings. NYNEX is the regional telephone company for the New York/New England area, with about 50,000 employees. NYNEX has made an unprecedented commitment to lifelong education of its front-line workers by establishing NYNEX University campuses throughout its operating regions. GIMMe technology is used as part of this effort, aimed to train workers to keep up with the rapid changes in their field through (1) a deeper understanding of emerging technologies, (2) competence with computational tools for finding and communicating new knowledge, and (3) a new emphasis on peer-to-peer learning in the workplace.
L3D Center (including the proposed project ). Our research center aims to develop computational support and conventions of use that enable us to be a learning research community. We will create organizational memories for our center, as well as for the proposed project. This self-application of our theories will give us first-hand experience with the strengths and limitations of our conceptual framework and technology.
University of Colorado Courses. University courses have traditionally been based on instructionist educational strategies, emphasizing fixed curricula, memorization, and decontextualized learning. The proposed project will continue our standing commitment to exploring new models of education that emphasize peer-to-peer learning through projects and discussion-oriented classrooms. We will use project prototypes in our own classrooms, where students will explore and reflect upon innovative applications of organizational memory.
![]()
Section 6. Work Plan
Year 1. Our initial focus will be on careful analysis of the current practices of the LAN design community at the University of Colorado and our own research group. We will work with an anthropologist to understand the existing practices of communities we collaborate with. Our goal will be to extend the unit of analysis from an individual working and learning to an organizational focus. System-building efforts in the first year will focus on the implementation of a core WebNet system. We will employ available technologies and our prior system mechanisms and extend them as needed.
Year 2. In the second year our emphasis will be on envisioning and enabling new ways of working, learning, and collaborating. We will work closely with several communities to create organizational memory seeds. The seeds will define initial community-specific organizational memories. The seeding process will be grounded by the creation and collaborative assessment of prototypes, with communication about the prototypes captured within the organizational memories. This approach will interleave system-building and assessment, and capture a history of the seeding process that will serve project assessment as well as the ongoing evolution of the systems. We will embed logging mechanisms in the organizational memories to facilitate tracking of the evolution of both information content and structure. In this year we will extend our system functionality with perspectives and a scripting language.
Year 3. The final year of the project will have two primary foci: (1) the use and sustainability of organizational memories by the communities of practice, and (2) an integrative framework for organizational learning in a variety of settings. Assessment of organizational learning in communities will be both quantitative and qualitative. Logs of information use and evolution will provide data about the mechanisms most used and about the dynamics of the organizational memory. By analyzing the usage logs in conjunction with user interviews, we will assess how well the mechanisms and systems supported the sustainability of these information spaces as useful sources of organizational memory under changing conditions. Our assessment of organizational learning in the research settings will lead to an integrated conceptual framework for organizational memories and a generic architecture of computational support for organizational learning.
![]()
![]()
Go to top of this page
|
|
WWW http://www.cis.drexel.edu |
Return to Gerry Stahl's Home Page
Send email to Gerry.Stahl@drexel.edu
This page last modified on January 05, 2004